
Le développement IoT ne se limite pas à brancher des capteurs et à faire remonter deux variables vers le cloud. Il faut faire tenir ensemble du code embarqué, des échanges réseau, une couche applicative exploitable et une sécurité qui résiste au terrain. Je détaille ici ce que recouvre le métier, les briques techniques qui comptent vraiment et les décisions qui évitent de transformer un prototype prometteur en système fragile.
Les repères essentiels pour comprendre le métier IoT
- Le rôle est hybride: firmware, réseau, cloud, données et sécurité se croisent dans le même projet.
- MQTT reste central pour la télémétrie, mais HTTP, WebSockets, BLE ou LoRaWAN gardent leur place selon le cas d’usage.
- Un objet connecté impose des contraintes absentes du web classique: mémoire limitée, énergie, réseau intermittent et mises à jour à distance.
- Un système sérieux prévoit dès le départ l’identité de chaque appareil, le chiffrement, les logs, les tests terrain et l’OTA.
- En 2026, l’edge computing et la supervision opérationnelle comptent autant que l’application visible.
Ce que recouvre vraiment le métier
Je vois le développeur IoT comme un pont entre trois mondes: l’électronique, le réseau et le logiciel. Selon le projet, il peut écrire du firmware, configurer un broker MQTT, exposer une API, surveiller des métriques ou corriger une dérive de consommation électrique après un test terrain. Ce n’est pas un rôle décoratif. C’est souvent lui qui transforme une idée de produit connecté en système qui fonctionne sans supervision permanente.
En France, ce profil apparaît surtout dans l’industrie, la domotique, la logistique, l’énergie, la santé ou les objets grand public. Dans ces contextes, le bon réflexe n’est pas d’empiler les outils, mais de comprendre ce que chaque couche doit garantir: mesure fiable, transport robuste, stockage propre, exploitation simple. C’est cette logique d’ensemble qui fait la différence entre un gadget et une vraie plateforme IoT. Et c’est précisément pour cela qu’il faut distinguer l’IoT du développement web classique.
Pourquoi l’IoT ne se programme pas comme une application web
Le piège le plus courant consiste à transposer les réflexes du web vers un appareil embarqué. Sur un serveur, on corrige souvent en ajoutant de la mémoire, du calcul ou un service de plus. Sur un objet connecté, ce luxe n’existe pas. La mémoire se compte souvent en kilo-octets ou en quelques mégaoctets, la connexion peut disparaître, et la batterie ne pardonne pas les traitements inutiles.
| Critère | Développement web | IoT | Impact concret |
|---|---|---|---|
| Ressources | CPU et RAM relativement généreux | Mémoire et énergie limitées | Code compact, logs ciblés, dépendances choisies avec soin |
| Connexion | Stable et permanente | Intermittente, parfois coûteuse | Reprises, buffers, file d’attente et tolérance aux coupures |
| Déploiement | Serveur central ou application web | Parc distribué d’appareils physiques | Provisioning, gestion de flotte et mises à jour OTA |
| Tests | Navigateurs, API, environnements de staging | Laboratoire, matériel réel, contraintes radio | Simulateur utile, mais tests terrain indispensables |
| Sécurité | Comptes, sessions, jetons | Identité par appareil, certificats, clés embarquées | Pas de partage de secrets et peu de place pour l’improvisation |
Ces contraintes changent tout dans la manière d’écrire le code. Je ne démarre jamais un projet IoT en pensant d’abord à l’interface graphique. Je commence par la qualité du signal, la fréquence des messages, le comportement en cas de coupure et la façon dont l’appareil se remet debout après un incident. C’est seulement après cette étape que le produit devient vraiment exploitable. À partir de là, l’architecture technique devient la vraie question.
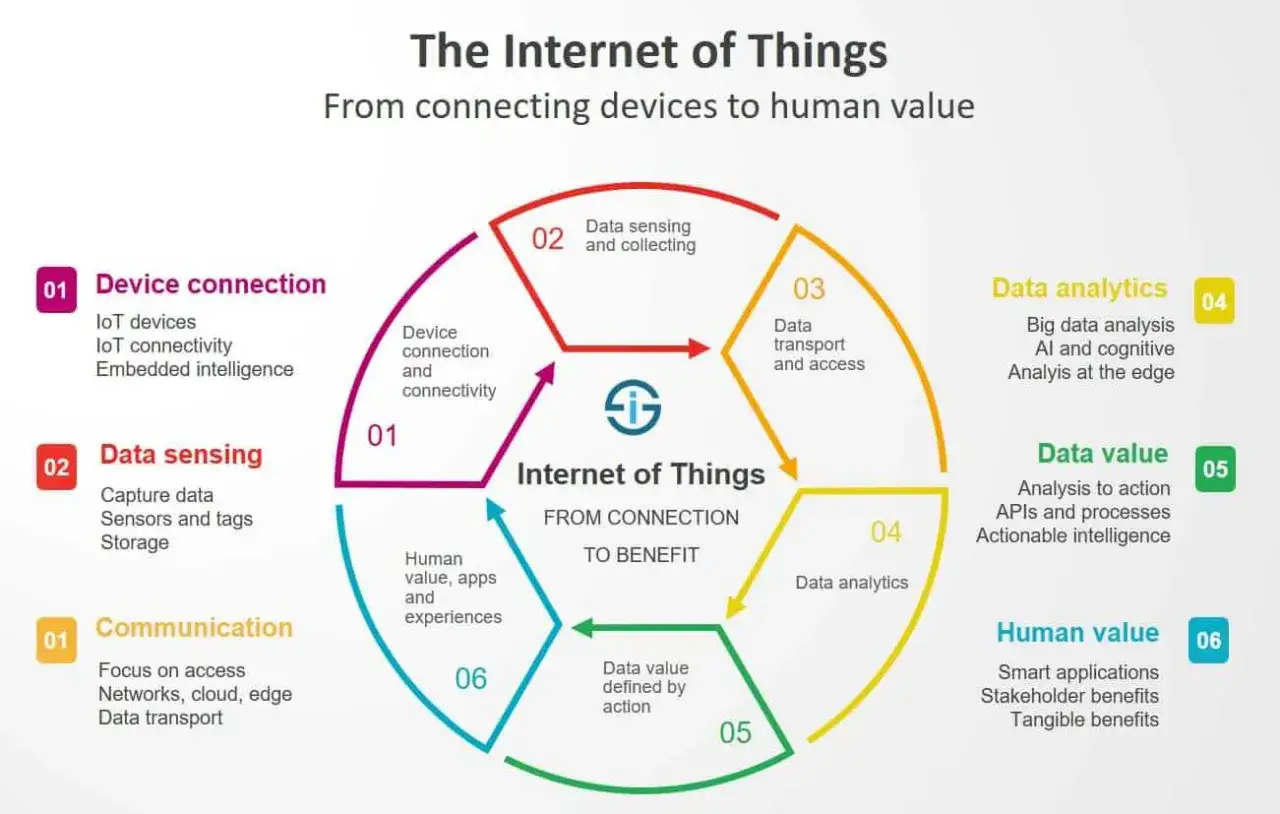
Comment une architecture IoT propre se découpe
Une architecture IoT saine repose généralement sur cinq couches: l’objet, la connectivité, la passerelle éventuelle, la plateforme cloud et la supervision. L’objet mesure ou agit localement. La connectivité transporte les événements. La passerelle agrège, filtre ou traduit si le périphérique ne parle pas directement IP. Le cloud stocke, corrèle et expose. Enfin, la supervision permet aux équipes d’opérer le système sans ouvrir le capot à chaque alerte.
Quand je peux aller en direct vers le cloud, je le fais surtout si l’objet parle IP, reste correctement alimenté et dispose d’une liaison stable. Dès qu’il faut agréger plusieurs capteurs, franchir un protocole radio non IP ou faire un premier filtrage local, j’introduis une passerelle. C’est souvent la meilleure décision pour réduire le trafic inutile, améliorer la latence et éviter que tout le système dépende d’une seule connexion extérieure.
- Objet pour la mesure et l’action locale, avec un firmware sobre.
- Transport pour faire circuler les données avec le bon compromis entre portée, coût et énergie.
- Broker pour gérer le modèle publication/abonnement, très pratique pour la télémétrie.
- Cloud pour l’ingestion, les règles métier, l’historisation et l’API.
- Supervision pour les tableaux de bord, les alertes et l’exploitation quotidienne.
Pour la télémétrie, je privilégie souvent MQTT parce qu’il est léger et adapté aux flux d’objets. Pour des opérations ponctuelles comme la configuration, le diagnostic ou une intégration simple, HTTP garde un intérêt réel. Et quand la latence locale ou la confidentialité deviennent prioritaires, je pousse davantage de logique vers l’edge. Cette découpe évite de surcharger le cloud avec des tâches qui devraient rester au plus près du terrain. Une fois cette base claire, il faut choisir la pile logicielle qui tient la route.
La pile logicielle que je privilégie en 2026
En 2026, je ne vois pas un projet IoT sérieux sans MQTT 5, sans stratégie OTA et sans gestion d’identité par appareil. Côté firmware, C et C++ restent les bases les plus courantes sur microcontrôleur, avec des environnements comme FreeRTOS ou Zephyr selon le niveau de contrôle attendu. Sur les passerelles et les services voisins, Python, Node.js, Go et Linux reviennent souvent, parce qu’ils accélèrent l’intégration et simplifient l’orchestration.
| Niveau | Technologies fréquentes | Pourquoi je les garde en tête |
|---|---|---|
| Firmware | C, C++, FreeRTOS, Zephyr | Empreinte légère, contrôle précis du matériel, temps réel plus prévisible |
| Connectivité | MQTT 5, HTTPS, WebSocket Secure, BLE, LoRaWAN, Wi-Fi, Thread | Le bon choix dépend de la portée, de l’énergie, de l’interopérabilité et de la latence |
| Passerelle | Linux, Python, Node.js, Go, Docker | Très utile pour agréger, transformer et sécuriser avant l’envoi au cloud |
| Backend | Python, TypeScript, Go, SQL, bases time-series | Bon compromis entre ingestion de flux, API, règles et analytique |
| Supervision | React, Vue, Grafana, outils d’alerting | Un dashboard lisible fait gagner du temps aux équipes terrain et support |
| Ops | CI/CD, tests matériels, OTA, observabilité | Sans cela, la plateforme vit mal dès que le parc grossit |
Je vois aussi Rust progresser, surtout quand la sûreté mémoire et la rigueur système comptent beaucoup. Mais je ne le mets pas encore devant C et C++ par défaut dans un projet où l’écosystème, les bibliothèques matérielles et la maturité des outils restent décisifs. Le bon choix n’est pas celui qui fait moderne sur une slide, c’est celui qui supporte le produit dans trois ans. Et cette stabilité logicielle n’a de valeur que si la sécurité est traitée comme une exigence de base.
Sécurité, fiabilité et mises à jour ne sont pas des détails
Sur un projet connecté, la sécurité n’est pas une couche qu’on ajoute à la fin. Elle doit être présente dès la première ligne de code utile. Je considère comme non négociables une identité unique par appareil, des communications chiffrées en TLS, des secrets correctement stockés, un firmware signé et un mécanisme de mise à jour capable de revenir en arrière si quelque chose casse.
- Une identité par appareil, pour éviter les secrets partagés qui finissent toujours mal.
- Des communications chiffrées, parce qu’un objet qui parle en clair finit vite exposé.
- Un démarrage sécurisé, pour empêcher le chargement d’un firmware modifié.
- Une OTA testée, avec rollback, sinon chaque correction devient un risque opérationnel.
- Des logs et des métriques, pour comprendre ce qui se passe sans brancher un câble sur chaque unité.
La fiabilité suit la même logique. Il faut prévoir les pertes de réseau, les coupures d’alimentation, les messages dupliqués, les horloges désynchronisées et les montées en charge imprévues. Dans la pratique, je préfère toujours un système un peu moins ambitieux mais observable, qu’une architecture brillante incapable d’expliquer ses erreurs. Une fois ces garde-fous en place, on peut enfin passer du prototype au produit sans se mentir sur le niveau de maturité réel.
Passer du prototype au produit sans se faire piéger
Le passage du prototype à l’industrialisation est souvent le moment où les projets IoT se dégradent. Je le découpe en quatre étapes: valider l’usage, stabiliser le message, tester dans les conditions réelles, puis préparer la flotte. Ce n’est pas seulement une question de code, c’est une question de discipline produit.
- Valider l’usage en conditions simples, pour vérifier que le besoin métier est réel.
- Stabiliser le format des données, parce qu’un schéma mal pensé coûte cher à corriger plus tard.
- Mesurer le comportement terrain, notamment la portée radio, l’autonomie et les pertes de messages.
- Préparer le cycle de vie avec provisioning, supervision et mise à jour distante.
Les erreurs les plus coûteuses sont souvent les mêmes: choisir un protocole parce qu’il est à la mode, reporter la stratégie OTA, oublier l’observabilité, négliger la consommation électrique ou concevoir le tableau de bord avant d’avoir une donnée propre. Je préfère aussi éviter les architectures trop centralisées au début, car elles donnent une illusion de simplicité qui s’effondre dès que le parc grandit. Quand la base technique est saine, la question suivante devient plus pratique: que faut-il apprendre en priorité pour tenir ce rôle dans la durée ?
Par où je commencerais si je devais former un profil IoT aujourd’hui
Si je devais construire un plan d’apprentissage en partant de zéro, je viserais d’abord la maîtrise du firmware simple, puis la communication réseau, puis l’exploitation de bout en bout. Le but n’est pas de tout savoir tout de suite. Le but est d’être capable d’emmener un objet du capteur jusqu’au dashboard, puis de le maintenir dans le temps.
- Comprendre le microcontrôleur, la mémoire, les interruptions et les bases du C ou du C++.
- Maîtriser un protocole de messagerie, en pratique MQTT, avec ses notions de topic, QoS et session.
- Travailler un premier backend léger pour ingérer, filtrer et stocker les données.
- Construire un petit tableau de bord pour voir les anomalies, pas seulement les courbes jolies.
- Ajouter ensuite une vraie chaîne OTA et un mécanisme de logs exploitables.
Je conseille aussi de faire au moins un projet concret avec une contrainte réelle, par exemple une mesure d’autonomie, un réseau instable ou une remontée d’alerte en temps réel. C’est là que les connaissances deviennent utiles. Le bon spécialiste IoT n’est pas celui qui accumule les mots-clés techniques, mais celui qui sait arbitrer entre consommation, sécurité, latence et exploitabilité quand le système sort du labo. C’est ce mélange qui transforme un objet connecté en produit durable.
Si je devais garder une seule idée, ce serait celle-ci: dans l’IoT, la qualité du code compte, mais la qualité du système compte davantage. Je commencerais toujours par la contrainte la plus dure du terrain, qu’il s’agisse de l’autonomie, de la couverture réseau, du volume de données ou de la sécurité, puis je construirais le reste autour de cette limite. C’est cette discipline qui fait la différence entre un prototype séduisant et une solution connectée réellement fiable.