
Le multi threading permet à un programme d’avancer sur plusieurs tâches sans bloquer toute l’application sur une seule opération. C’est un levier précieux pour les interfaces réactives, les serveurs et les traitements qui passent beaucoup de temps à attendre le réseau, le disque ou une API. Ici, je vais clarifier le fonctionnement réel des threads, montrer quand ils apportent un gain concret, détailler les pièges à éviter et aider à choisir entre threads, processus et asynchrone.
Les points essentiels à garder en tête avant d’ajouter des threads
- Un thread est un fil d’exécution à l’intérieur d’un même processus, avec une mémoire largement partagée.
- La concurrence ne signifie pas toujours parallélisme réel sur plusieurs cœurs.
- Le gain est souvent net sur les tâches d’entrée-sortie, mais beaucoup plus faible sur le calcul pur.
- Sans synchronisation, les données partagées deviennent vite la principale source de bugs.
- Verrous, sémaphores et conditions servent à coordonner proprement les accès, pas à accélérer automatiquement le code.
- Pour les charges très CPU, un autre modèle peut être plus rentable que les threads.
Ce que fait vraiment le multithreading
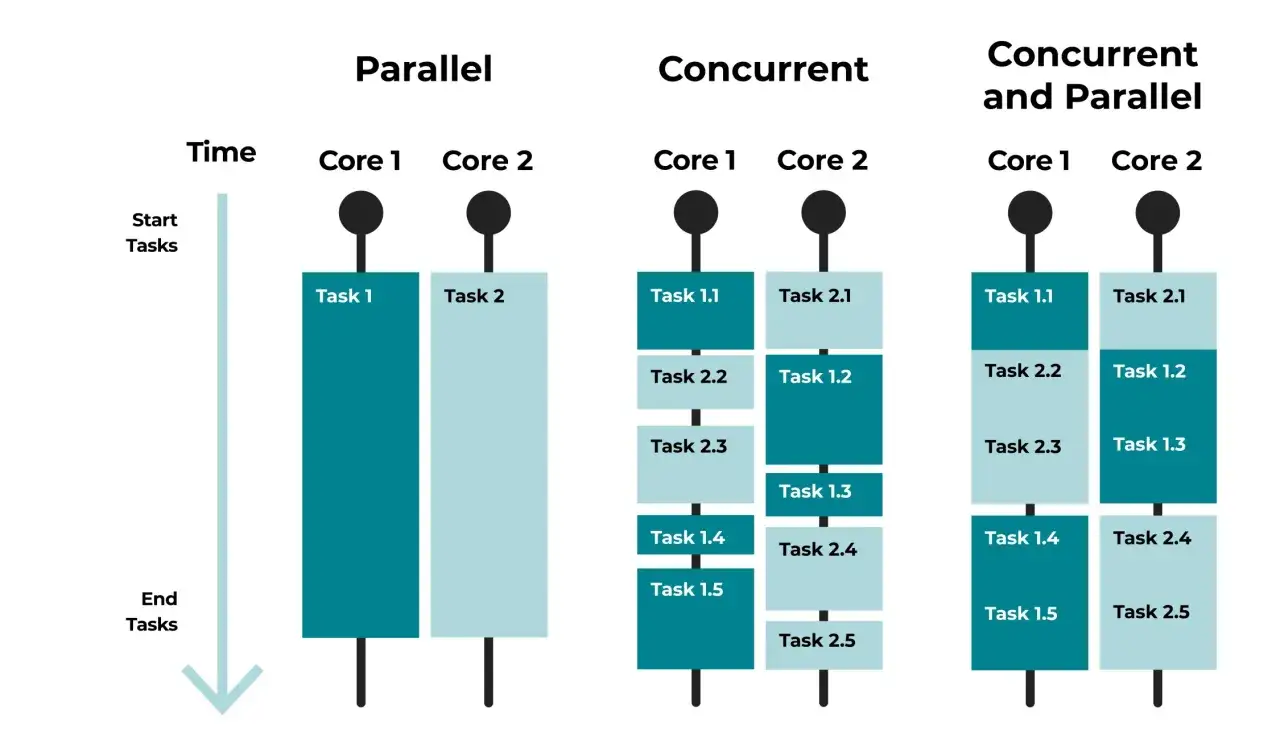
Un thread n’est pas un mini-programme indépendant. C’est plutôt un chemin d’exécution supplémentaire qui vit à l’intérieur du même processus, partage la mémoire, les fichiers ouverts et une bonne partie du contexte applicatif. En pratique, cela veut dire qu’un thread peut travailler pendant qu’un autre attend une réponse réseau, une lecture disque ou une opération lente.
Je distingue toujours deux idées que l’on mélange facilement : la concurrence et le parallélisme. La concurrence décrit le fait que plusieurs tâches progressent de façon entrelacée. Le parallélisme, lui, suppose qu’elles s’exécutent réellement en même temps sur plusieurs cœurs. Un programme multithreadé peut donc être concurrent sans être vraiment parallèle si le runtime ou le matériel ne le permet pas.
Le rôle du système d’exploitation est central. Il répartit le temps processeur entre les threads via l’ordonnanceur, ce qui donne l’impression d’une activité simultanée. C’est très utile pour masquer les temps d’attente, mais cela n’annule pas les limites physiques du CPU. Si le travail consiste surtout à calculer, ajouter des threads ne crée pas magiquement plus de puissance.
La conséquence pratique est simple : avant de parler performance, il faut d’abord parler nature de charge. C’est exactement ce qui guide le choix des outils dans la suite.
Quand cette approche apporte un vrai gain
Le multithreading devient intéressant dès qu’une application alterne calcul court et attente longue. Je pense notamment aux clients réseau, aux interfaces graphiques, aux serveurs web, aux collecteurs de logs ou aux pipelines qui lisent, transforment et réécrivent des données par lots.
| Cas d’usage | Pourquoi les threads aident | Point d’attention |
|---|---|---|
| Appels API, base de données, microservices | Un thread peut continuer pendant qu’un autre attend une réponse | Limiter le nombre de threads pour éviter l’emballement |
| Interface utilisateur | L’UI reste réactive pendant qu’un travail lourd s’exécute en arrière-plan | Ne jamais toucher l’UI depuis un thread non prévu pour cela |
| Traitement de fichiers | Lecture, parsing et écriture peuvent être mieux répartis | Le disque devient parfois le goulot d’étranglement |
| Calcul intensif pur | Gain limité si le runtime ne permet pas une exécution parallèle effective | Les processus ou un autre modèle peuvent être plus efficaces |
La documentation Python le rappelle très bien : le choix entre threads et autres formes de concurrence dépend surtout de la part d’attente et de calcul dans la tâche. En clair, si l’application passe son temps à attendre, les threads ont de la valeur ; si elle passe son temps à calculer, le bénéfice est souvent décevant.
Dans un service web, par exemple, un thread peut préparer une réponse pendant qu’un autre traite une requête entrante. C’est précisément ce qui permet de garder un débit stable sans geler tout le serveur dès qu’une opération réseau ralentit.
Les mécanismes à maîtriser pour éviter les bugs
Le plus gros malentendu sur les threads, c’est de croire qu’il suffit de les lancer pour que tout s’organise tout seul. En réalité, dès qu’ils partagent des données, il faut gérer l’accès à ces données avec méthode.
- Mutex ou lock : un seul thread à la fois entre dans une section critique, c’est-à-dire la portion de code qui touche à une ressource partagée.
- Sémaphore : plusieurs threads peuvent passer, mais dans une limite contrôlée. C’est utile pour borner le nombre de travailleurs simultanés.
- Condition : un thread attend qu’un état précis soit atteint avant de continuer.
- Variable atomique : une opération est exécutée de manière indivisible, sans risque d’interruption intermédiaire sur l’état protégé.
- Pool de threads : un ensemble de threads réutilisés pour exécuter des tâches, ce qui évite de créer et détruire des fils d’exécution à chaque requête.
À mon sens, le pool de threads est souvent le premier vrai gain d’ingénierie. Il évite le surcoût de création de threads à répétition et donne un cadre plus propre pour distribuer le travail. Mais ce n’est pas une solution universelle : si les tâches sont trop courtes, la coordination peut coûter plus cher que le travail lui-même.
Il faut aussi connaître deux incidents classiques. Le deadlock apparaît quand deux threads se bloquent mutuellement en attendant chacun une ressource détenue par l’autre. La race condition survient quand l’ordre d’exécution change le résultat final, ce qui rend le bug intermittent et difficile à reproduire.
Quand je vois un projet qui “va plus vite en théorie” mais qui devient instable, le problème vient presque toujours d’une synchronisation sous-estimée. On ne corrige pas ça avec plus de threads, mais avec une meilleure discipline d’accès aux données.
Les erreurs qui ruinent les gains
Le piège n’est pas seulement technique, il est souvent architectural. Un programme multithreadé mal pensé peut être plus lent qu’une version séquentielle, tout en étant beaucoup plus dur à maintenir.
- Partager trop d’état mutable entre les threads.
- Verrouiller trop large, ce qui crée de la contention et force les threads à attendre inutilement.
- Créer trop de threads, au point de saturer l’ordonnanceur et d’augmenter les changements de contexte.
- Ignorer l’ordre des verrous, ce qui ouvre la porte aux deadlocks.
- Mesurer seulement le temps moyen sans regarder la latence réelle, les pics de charge ou le débit total.
Je vois aussi souvent une erreur de stratégie : on ajoute des threads pour “aller plus vite” alors que le vrai problème est ailleurs, par exemple un algorithme inefficace, une requête trop verbeuse ou un accès disque mal structuré. Dans ce cas, le multithreading masque temporairement le symptôme sans traiter la cause.
La règle la plus saine reste la même depuis longtemps : benchmarker avant et après, avec une charge réaliste. Sans chiffres mesurés, les impressions de vitesse sont trompeuses.
Multithreading, processus ou asynchrone
Le bon choix dépend du type de travail à effectuer, du langage utilisé et du niveau de complexité acceptable. Je résume souvent la décision de cette façon : threads pour le partage rapide d’état et l’attente, processus pour le calcul intensif, asynchrone pour beaucoup d’I/O avec peu de threads.
| Approche | Forces | Limites | À privilégier pour |
|---|---|---|---|
| Threads | Partage mémoire simple, bonne réactivité sur les attentes | Synchronisation délicate, bugs difficiles à reproduire | Réseau, I/O, UI, tâches mixtes |
| Processus | Isolation forte, parallélisme réel plus facile à exploiter | Coût mémoire et communication plus élevés | Calcul lourd, traitements indépendants |
| Asynchrone | Très efficace pour gérer beaucoup d’attentes avec peu de threads | Change le style de programmation, pas idéal pour le CPU pur | Serveurs I/O intensifs, clients réseau, pipelines événementiels |
Sur Python classique, le sujet est particulièrement parlant : les threads restent utiles pour les tâches d’entrée-sortie, mais le gain sur le calcul pur est limité dans l’exécution standard. Des versions free-threaded existent désormais dans certains environnements, mais ce n’est pas la configuration par défaut. C’est un bon exemple de nuance importante : l’outil est bon, mais le runtime peut changer complètement le résultat.
En pratique, je choisis rarement les threads par réflexe. Je les choisis quand ils simplifient la gestion de l’attente sans dégrader la lisibilité ni la robustesse du code. Si la complexité monte trop vite, je regarde d’abord une autre approche.
Le test que j’applique avant de multiplier les threads
Avant d’introduire plus de threads dans une base de code, je passe par une vérification très concrète :
- La tâche est-elle surtout en attente, ou surtout en calcul ?
- Les données partagées peuvent-elles être réduites ou isolées ?
- Le code restera-t-il compréhensible après ajout de la synchronisation ?
- Existe-t-il un besoin réel de réactivité ou de débit, mesurable avec un benchmark ?
- Peut-on limiter le nombre de travailleurs avec un pool plutôt que de lancer des fils sans borne ?
- Le plan de gestion d’erreurs et d’arrêt propre est-il clair ?
Si je n’ai pas une réponse solide à ces questions, je considère généralement que le projet n’est pas prêt pour une parallélisation fine. C’est souvent là que l’expérience compte le plus : les threads ne sont pas difficiles parce qu’ils sont compliqués en soi, mais parce qu’ils rendent visibles des défauts d’architecture qu’un programme séquentiel peut longtemps cacher.
Le bon usage du multithreading n’est donc pas une démonstration de puissance. C’est un choix d’ingénierie précis, utile quand il absorbe l’attente, protège la réactivité et reste maîtrisable sur la durée.