
Décoder un code ASCII revient à transformer une suite de nombres en texte lisible, mais la méthode change vite selon la base utilisée, les séparateurs et l’encodage réel du fichier. Dans les scripts, les logs ou les échanges réseau, je commence toujours par vérifier ces trois points avant de convertir quoi que ce soit. Une fois ce cadre posé, la lecture devient simple et l’erreur la plus fréquente disparaît presque d’elle-même.
Les points essentiels pour décoder un texte ASCII sans erreur
- ASCII standard couvre 128 valeurs, de 0 à 127, sur 7 bits.
- Les codes 0 à 31 et 127 sont des caractères de contrôle, donc souvent invisibles à l’écran.
- Les caractères imprimables vont de 32 à 126, avec l’espace en code 32.
- Une suite de nombres n’est lisible que si l’on connaît sa base: décimal, hexadécimal ou binaire.
- Pour automatiser la conversion,
chr()en Python etString.fromCharCode()en JavaScript couvrent la plupart des cas ASCII. - Dès qu’il y a des accents, des symboles rares ou des emojis, il faut envisager UTF-8 ou une autre page de codes.
Ce qu’il faut comprendre avant de décoder un code ASCII
ASCII n’est pas une langue ni un chiffrement: c’est une table de correspondance entre des nombres et des caractères. Le standard de base tient sur 7 bits, donc sur 128 valeurs possibles, ce qui explique pourquoi il reste limité aux lettres latines simples, aux chiffres, à la ponctuation courante et à quelques symboles techniques.
Dans la pratique, deux familles de codes cohabitent. D’un côté, les caractères de contrôle servent à commander l’affichage ou la transmission du texte; de l’autre, les caractères imprimables représentent ce que l’on voit réellement à l’écran. C’est cette distinction qui évite de confondre un vrai problème d’encodage avec un simple retour à la ligne ou une tabulation cachée.
Je garde aussi un réflexe simple: si la séquence semble contenir des valeurs supérieures à 127, je ne parle plus vraiment d’ASCII pur. On bascule alors vers un encodage plus large, souvent UTF-8, et il faut changer de grille de lecture. Une fois cette frontière comprise, la lecture de la table devient beaucoup plus fiable.
Le point suivant consiste donc à savoir lire cette table sans ambiguïté, surtout quand les nombres sont notés en décimal, en hexadécimal ou en binaire.
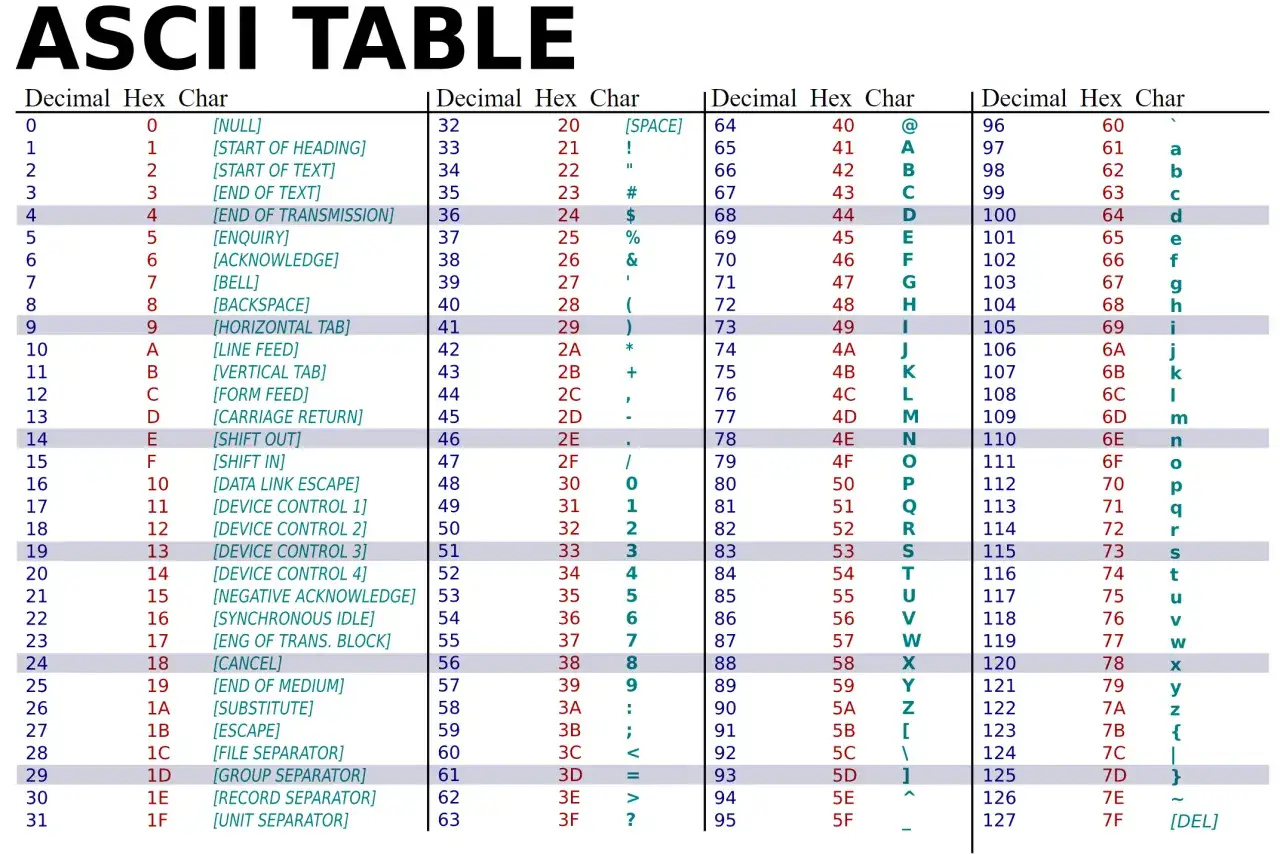
Lire une table ASCII sans se tromper sur la base
Le piège classique, c’est de croire qu’un nombre est toujours écrit en décimal. En réalité, une même valeur peut être présentée en décimal, en hexadécimal ou en binaire, et le résultat change complètement si l’on interprète mal la base. Pour éviter ça, je vérifie toujours le format d’origine avant de convertir.
| Décimal | Hexadécimal | Binaire | Caractère | Rôle |
|---|---|---|---|---|
| 32 | 0x20 | 0010 0000 | espace | Séparateur visible, mais discret |
| 65 | 0x41 | 0100 0001 | A | Majuscule de base |
| 90 | 0x5A | 0101 1010 | Z | Fin de l’alphabet majuscule |
| 97 | 0x61 | 0110 0001 | a | Minuscule de base |
| 10 | 0x0A | 0000 1010 | LF | Saut de ligne |
| 13 | 0x0D | 0000 1101 | CR | Retour chariot |
| 127 | 0x7F | 0111 1111 | DEL | Caractère de suppression |
Dans les échanges techniques, les séquences sont souvent notées en blocs séparés par des espaces, des virgules ou des sauts de ligne. En revanche, une chaîne compacte comme 72101108108111 ne se lit pas proprement sans contexte, parce qu’on ne sait pas où couper les chiffres. C’est là que les faux décodages commencent: non pas dans la conversion elle-même, mais dans l’interprétation du format.
Une fois la base clarifiée et les valeurs séparées correctement, on peut passer à une méthode de décodage simple et reproductible.
Décoder un message ASCII pas à pas
Quand je dois transformer une séquence en texte, je procède toujours dans le même ordre. Cela évite de “lire au feeling” et de fabriquer un résultat plausible mais faux.
- Je repère la base utilisée: décimal, hexadécimal ou binaire.
- Je vérifie le séparateur entre les valeurs: espace, virgule, tiret ou bloc compact.
- Je convertis chaque code en caractère à partir de la table ASCII.
- Je contrôle les caractères de contrôle comme
LFouCR, qui peuvent modifier l’affichage. - Je relis le résultat final pour confirmer qu’il correspond bien au contexte.
Exemple simple en décimal: 66 111 110 106 111 117 114 donne Bonjour. Le même message en hexadécimal s’écrit 42 6F 6E 6A 6F 75 72. Ce genre de correspondance est utile parce qu’il montre immédiatement si l’on est devant une suite de valeurs lisibles ou devant une donnée mal découpée.
Il faut aussi accepter une limite importante: sans séparateur ou sans longueur fixe, certaines séquences sont ambiguës. Par exemple, une chaîne compacte peut parfois correspondre à plusieurs découpages possibles. Dans ce cas, je ne force jamais une interprétation; je cherche plutôt le format d’origine ou le code qui l’a produite.
À partir de là, la conversion devient très rapide dès qu’on l’automatise dans un langage de programmation.Décoder en programmation avec Python et JavaScript
Pour un script court, Python reste le plus direct. Pour un environnement web, JavaScript est plus naturel. Les deux permettent de reconstruire un texte à partir d’une liste de codes ASCII, à condition de rester dans la plage 0 à 127.
| Langage | Fonction utile | Usage le plus pratique |
|---|---|---|
| Python |
chr() et ord()
|
Convertir un entier en caractère et vérifier le code d’un caractère |
| JavaScript |
String.fromCharCode() et charCodeAt()
|
Reconstruire une chaîne à partir de codes numériques |
| JavaScript côté navigateur | TextDecoder |
Décoder des octets quand on travaille avec un flux binaire |
En Python, le plus simple ressemble à ceci:
codes = [66, 111, 110, 106, 111, 117, 114]
texte = "".join(chr(n) for n in codes)
print(texte)En JavaScript, j’utilise souvent cette forme:
const codes = [66, 111, 110, 106, 111, 117, 114];
const texte = String.fromCharCode(...codes);
console.log(texte);Je préfère cette approche parce qu’elle reste lisible et facile à vérifier. Si je dois faire l’opération inverse, je repars simplement vers ord() en Python ou charCodeAt() en JavaScript pour contrôler que le texte source correspond bien aux valeurs attendues. Si les codes dépassent 127, je ne parle déjà plus d’un décodage ASCII strict, et je change d’outil ou d’encodage.
Mais cette simplicité a une contrepartie: dès qu’on sort de l’anglais de base, il faut arrêter de supposer qu’ASCII suffit.
Quand ASCII ne suffit plus pour le texte réel
Dans les textes français, c’est ici que les choses se compliquent. Les accents comme é, è, à ou ç ne font pas partie de l’ASCII standard. Si un fichier les contient, il faut regarder du côté d’un encodage plus riche, généralement UTF-8, ou parfois d’une ancienne page de codes.
| Format | Taille | Ce qu’il couvre | Limite principale |
|---|---|---|---|
| ASCII | 7 bits, 128 codes | Lettres anglaises de base, chiffres, ponctuation simple | Pas d’accents, pas d’emoji, pas de caractères étendus |
| “Extended ASCII” | 8 bits, 256 positions | Caractères supplémentaires selon la page de codes | Ambigu: plusieurs variantes incompatibles existent |
| UTF-8 | 1 à 4 octets par caractère | Tout Unicode, donc quasiment tous les alphabets modernes | Plusieurs octets pour les caractères non ASCII |
Le terme “extended ASCII” est trompeur, parce qu’il laisse croire à un standard unique alors qu’il n’y en a pas. En dépannage, c’est souvent là que naissent les textes illisibles, les caractères remplacés par des symboles bizarres et les erreurs de conversion. Je conseille donc de le traiter comme un raccourci historique, pas comme une norme stable.
Un autre point compte beaucoup en programmation et en sécurité: les caractères de contrôle. Une tabulation, un retour chariot ou un saut de ligne peuvent modifier la structure d’un fichier, d’un log ou d’une requête. Un décodage correct ne consiste donc pas seulement à “voir des lettres”, mais aussi à reconnaître les caractères invisibles qui changent le comportement du texte.C’est pour cela que je termine toujours par un dernier contrôle avant de valider le résultat.
Le contrôle final qui évite les faux décodages
Avant d’affirmer qu’une séquence est bien interprétée, je vérifie quatre choses simples. Elles prennent quelques secondes, mais elles évitent beaucoup d’erreurs inutiles.
- Je confirme la base utilisée par les nombres.
- Je vérifie que les valeurs restent dans la plage ASCII, donc entre 0 et 127.
- Je repère les caractères de contrôle qui peuvent déplacer le texte ou le couper visuellement.
- Je regarde si le résultat contient des accents, des symboles rares ou des emojis, ce qui indique presque toujours un autre encodage.
Si l’un de ces points ne colle pas, je ne force pas le décodage. Je repars sur l’hypothèse d’un autre format: UTF-8, une page de codes héritée, ou parfois simplement une erreur dans la source initiale. Cette discipline fait gagner du temps, surtout quand on manipule des journaux applicatifs, des paquets réseau ou des données exportées depuis un ancien système.
Au fond, décoder du code ASCII n’est pas une question de mémoire, mais de méthode: reconnaître la base, lire la table correctement, puis valider le résultat avec un regard critique. Dès que le texte dépasse l’anglais simple, je change de cadre et je pense encodage avant de penser conversion, car c’est souvent là que se trouve la vraie réponse.