")
Un bon test unitaire ne sert pas seulement à vérifier qu’un code “marche”. Il protège une règle métier précise, sur une entrée connue, avec une sortie attendue et sans dépendre de la base de données, du réseau ou de l’interface. Ici, je prends un exemple concret et réaliste pour montrer comment écrire, lire et juger un test unitaire sans tomber dans un modèle trop académique.
Les points essentiels à garder en tête avant de regarder l’exemple
- Un test unitaire valide une seule logique locale, pas tout le système.
- Le test doit être rapide, déterministe et facile à relire.
- L’approche la plus claire suit souvent le trio préparer, agir, vérifier.
- Un bon exemple teste aussi les cas limites et les erreurs attendues.
- Si une dépendance externe gêne la lecture, je l’isole avec un mock ou un double de test.
Ce que je veux montrer avec un vrai exemple
Quand je parle de test unitaire, je pense d’abord à une fonction pure ou à une méthode qui prend des données en entrée et retourne un résultat précis. C’est le terrain idéal pour apprendre, parce qu’on voit immédiatement ce qui est vérifié et pourquoi le test échoue.
Pour rendre l’idée utile, je pars d’une fonction de remise commerciale. Elle n’a rien d’exotique, mais elle ressemble à ce qu’on trouve souvent dans un backend, une API ou un service métier. C’est exactement le type de logique qui mérite d’être testé tôt, parce qu’une erreur de calcul se propage très vite dans toute l’application.
La documentation Python insiste d’ailleurs sur un point que je retrouve dans tous les projets sérieux: un cas de test doit rester autonome et exécutable isolément. C’est ce qui fait la différence entre un vrai test unitaire et un scénario flou qui dépend du reste du système.
Ce cadre étant posé, je peux montrer un exemple simple en Python avant de le décortiquer. C’est la façon la plus directe de comprendre la mécanique.
Un exemple concret de test unitaire en Python
Voici une fonction qui calcule une remise en pourcentage, puis deux tests unitaires qui vérifient son comportement normal et son comportement en cas d’erreur.
# remise.py
def calculer_remise(montant_ht, pourcentage):
if montant_ht < 0:
raise ValueError("Le montant doit être positif")
if not 0 <= pourcentage <= 100:
raise ValueError("Le pourcentage doit être compris entre 0 et 100")
return round(montant_ht * (1 - pourcentage / 100), 2)
# test_remise.py
import pytest
from remise import calculer_remise
def test_calculer_remise_standard():
# arrange
montant = 100
taux = 20
# act
resultat = calculer_remise(montant, taux)
# assert
assert resultat == 80.0
def test_calculer_remise_refuse_un_pourcentage_invalide():
with pytest.raises(ValueError):
calculer_remise(100, 140)
Ce petit exemple fait déjà l’essentiel du travail. Il montre une règle métier claire, il vérifie une valeur attendue, et il contrôle aussi une erreur de validation. C’est beaucoup plus utile qu’un test qui se contente de répéter le code de production sous une autre forme.
Je préfère ce genre d’exemple parce qu’il reste lisible en quelques secondes. Quand un test demande trop d’explications, c’est souvent le signal qu’il teste trop de choses à la fois ou qu’il s’appuie sur des dépendances mal isolées. C’est justement ce que je détaille maintenant.
Lire ce test ligne par ligne
Je résume souvent un test unitaire par un triptyque simple: préparer, agir, vérifier. En anglais, on parle d’AAA pour Arrange, Act, Assert. Ce n’est pas une formule magique, mais c’est un repère pratique pour éviter les tests confus.Préparer les données
Dans le premier test, je fixe un montant à 100 et une remise à 20. Cette préparation doit être minimale. Plus il y a de variables inutiles, plus le test devient difficile à comprendre et à maintenir.
Exécuter une seule action
Je lance ensuite calculer_remise(montant, taux). Un bon test unitaire ne devrait pas multiplier les appels ni simuler un parcours complet. Il cible une seule décision métier, une seule branche logique, une seule réponse attendue.
Lire aussi : Puissance en C - Évitez les pièges de `pow()` et du `^`
Vérifier un résultat précis
Enfin, j’utilise une assertion unique et explicite: le résultat doit valoir 80.0. Cette partie est le cœur du test. Si l’assertion est floue, le test ne dit plus grand-chose. Si elle est trop large, elle peut laisser passer des régressions.
Le second test vérifie l’exception. Là aussi, l’idée est simple: si le pourcentage dépasse 100, la fonction doit refuser l’entrée. Ce n’est pas un détail technique, c’est une règle métier. Dans les projets un peu sérieux, ce genre de garde-fou évite des erreurs bien plus coûteuses que le test lui-même.
Je trouve que c’est souvent à ce moment-là que les débutants comprennent vraiment l’intérêt du test unitaire: ce n’est pas un script qui “passe”, c’est une petite preuve automatisée qu’une règle précise tient encore. Et cette preuve n’a de valeur que si le test couvre aussi son périmètre réel.
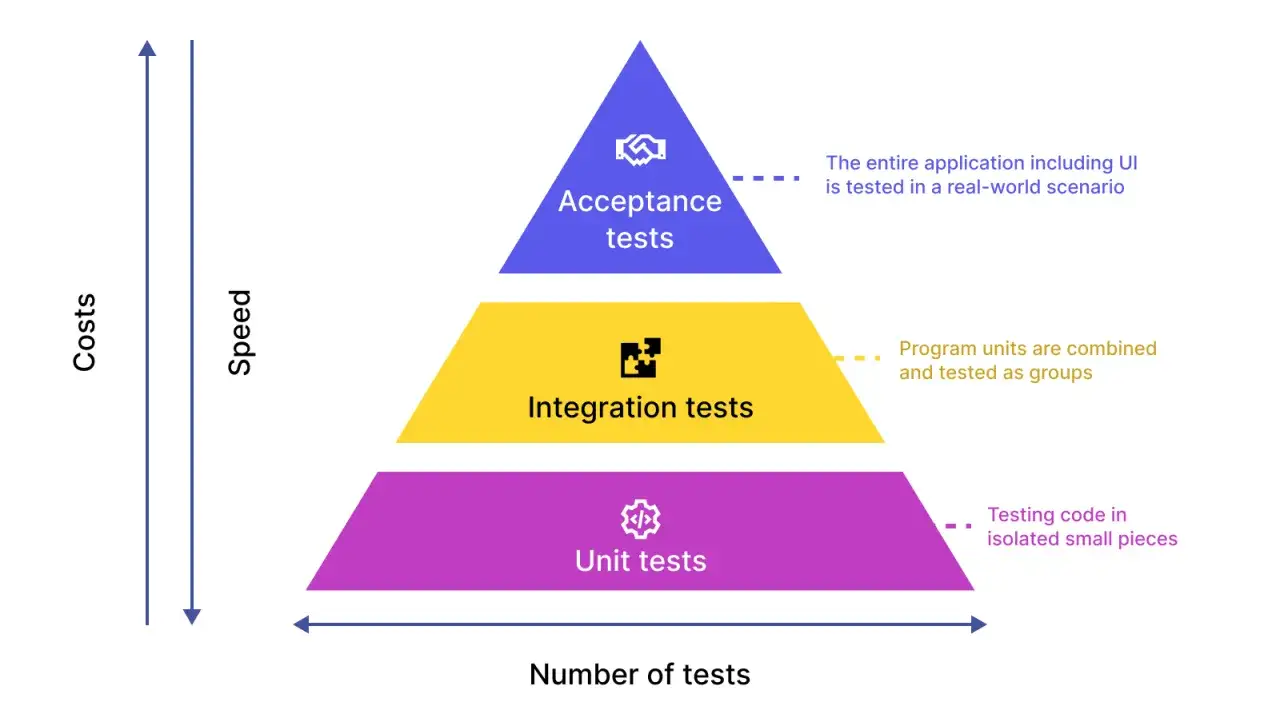
Ce que ce test couvre vraiment
Un test unitaire ne remplace pas tous les autres types de vérification. Il couvre un morceau de logique isolé, pas l’ensemble du système. Pour clarifier ce point, je compare souvent les trois niveaux les plus courants.
| Type de test | Portée | Vitesse | Ce que je vérifie en priorité |
|---|---|---|---|
| Test unitaire | Une fonction, une méthode, une classe | Généralement en millisecondes | La logique locale et les cas limites |
| Test d’intégration | Plusieurs composants ensemble | Souvent plus lent | Les échanges entre modules, base, API, filesystem |
| Test de bout en bout | Le parcours utilisateur complet | Le plus lent | Le comportement global du produit |
En pratique, je garde les tests unitaires pour les règles métier, les calculs, les validations et les transformations de données. Dès qu’une dépendance externe entre en jeu, je me pose une autre question: est-ce encore un test unitaire, ou est-ce déjà un test d’intégration déguisé ? La réponse change souvent la manière d’écrire le test.
Cette distinction est importante parce qu’elle évite une erreur fréquente: vouloir faire porter à un test unitaire le poids d’un scénario complet. C’est là que la suite devient lente, fragile et difficile à diagnostiquer. La suite suivante revient justement sur ces pièges.
Les erreurs que je vois le plus souvent
Le premier piège, c’est de tester trop large. Un test qui prépare une base de données, appelle une API et vérifie l’interface graphique n’est plus un test unitaire. Il peut être utile, mais il n’a plus la même fonction.
Le deuxième piège, c’est l’assertion molle. Vérifier seulement qu’“aucune erreur n’est levée” ne suffit pas. Je veux savoir ce qui doit être vrai, pas seulement ce qui ne s’est pas cassé.
Le troisième piège, c’est de dépendre du hasard. Une date courante, un ordre de liste non garanti, un appel réseau ou un état partagé rendent le test instable. Un test instable finit presque toujours par être ignoré, puis supprimé, ce qui annule tout son intérêt.
Le quatrième piège, c’est de dupliquer la logique de production dans le test. Si le test fait exactement le même calcul que le code qu’il prétend vérifier, il ne détecte plus grand-chose. Il devient une copie décorative, pas un filet de sécurité.
Le cinquième piège, enfin, c’est la dépendance mal isolée. Quand une fonction appelle un service externe, je préfère souvent un mock, c’est-à-dire un faux objet qui simule la dépendance. Cela me permet de tester le comportement attendu sans payer le coût ni l’aléa du service réel.
Quand ces erreurs disparaissent, la suite devient plus courte, plus nette et bien plus fiable. C’est aussi pour cela que l’on peut réutiliser la même logique dans d’autres langages sans réinventer la méthode à chaque fois.
Adapter la logique à JavaScript ou Java
Le langage change, mais l’idée reste identique. En JavaScript, j’écrirai souvent un test avec expect dans Jest ou Vitest. En Java, je retrouverai la même structure avec JUnit et des assertions équivalentes.
Par exemple, la vérification du calcul reste conceptuellement la même:
expect(calculerRemise(100, 20)).toBe(80);assertEquals(80.0, calculerRemise(100, 20));La syntaxe varie, mais la logique ne bouge pas: une entrée, une action, une sortie attendue. C’est pour cela qu’un bon exemple de test unitaire est si pédagogique. Il apprend une méthode, pas seulement une API de framework.
Dans les projets JavaScript modernes, je conseille généralement de garder les tests unitaires au plus près de la logique pure. Dans les projets Java, le même principe s’applique, que l’on utilise JUnit seul ou en complément d’outils de mock comme Mockito. Ce qui compte, ce n’est pas le nom de l’outil, mais la netteté de l’isolement.
Une fois cette base maîtrisée, il devient beaucoup plus simple de structurer une vraie stratégie de test sans empiler des scénarios inutiles.
Ce que je retiens avant d’écrire ma propre suite
Si je devais résumer l’approche en une règle simple, je dirais ceci: je teste d’abord la logique la plus stable, la plus locale et la plus rentable à protéger. Une fonction de calcul, une validation de formulaire, une transformation de données ou une règle de décision sont de très bons candidats.- Je commence par un cas nominal simple, puis j’ajoute un cas limite.
- Je garde chaque test court et explicite.
- J’évite de faire dépendre le test d’un système externe quand ce n’est pas nécessaire.
- Je préfère une suite de tests faciles à relire à une suite “complète” mais opaque.
Ce type d’exemple n’est pas spectaculaire, et c’est justement sa force. Il montre comment écrire un test qui protège réellement le code, sans bruit inutile ni dépendances parasites. Si je veux progresser vite, je pars de ce niveau de clarté, puis j’élargis seulement quand la logique du projet l’exige.