
Manipuler proprement des URL en PHP, ce n’est pas seulement ajouter un paramètre à une adresse. Il faut savoir lire une URL, reconstruire une requête sans casse, encoder chaque morceau au bon moment et éviter les validations trompeuses. Dans une application web, c’est souvent là que se cachent les liens cassés, les redirections fragiles et quelques failles discrètes.
Les points à maîtriser pour travailler proprement avec les URL en PHP
-
parse_url()sert à découper une URL, pas à la valider. -
http_build_query()est la façon la plus propre de générer une chaîne de requête. -
rawurlencode()convient surtout aux segments de chemin,urlencode()aux valeurs de requête. -
filter_var(..., FILTER_VALIDATE_URL)aide à filtrer, mais ne suffit pas à sécuriser un flux entier. - Les URL internationales, les redirections et les paramètres déjà présents demandent des vérifications supplémentaires.
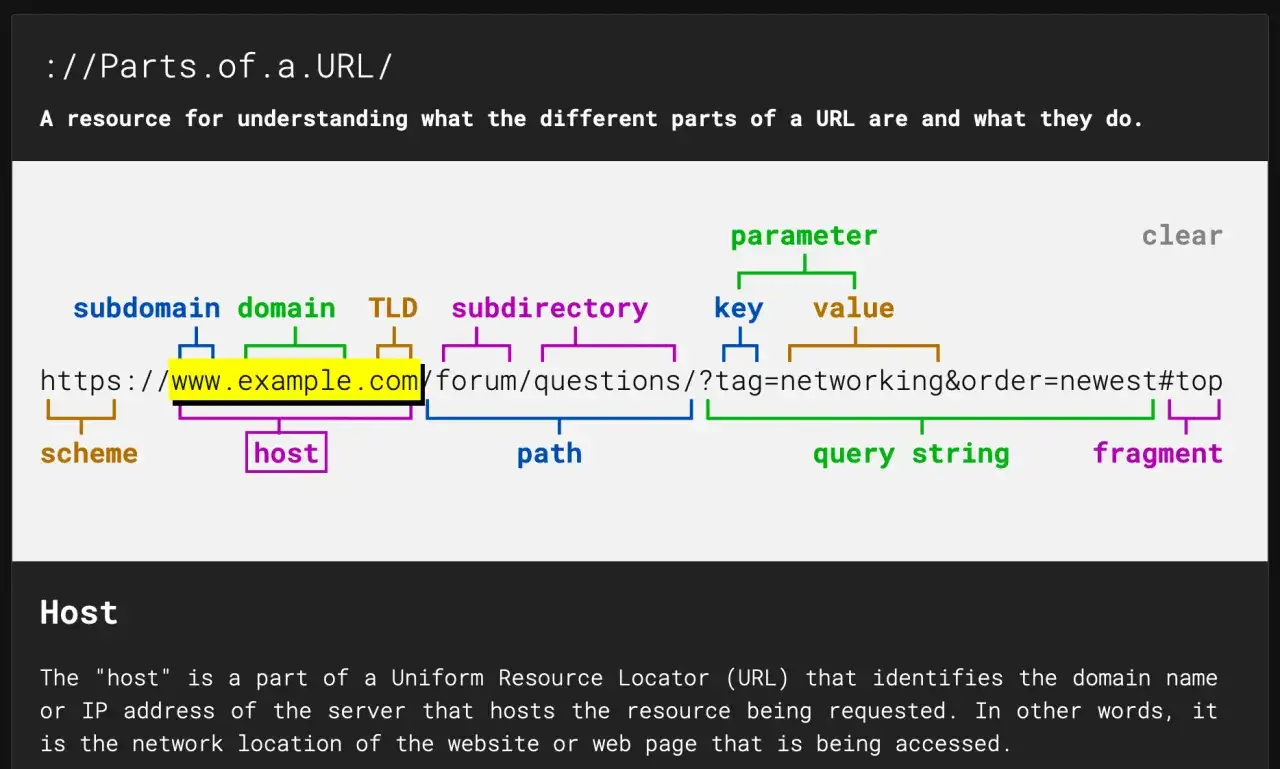
Ce que PHP sait vraiment faire avec une URL
Le premier réflexe, quand je dois traiter une adresse, c’est de la découper en composants. Avec parse_url(), PHP renvoie un tableau qui contient ce qui existe dans l’URL: schéma, hôte, port, chemin, requête, fragment, et parfois utilisateur ou mot de passe. C’est pratique pour comprendre ce que l’on a sous les yeux, mais il faut garder une idée simple en tête: cette fonction n’effectue pas une validation.
Elle accepte aussi des URL partielles ou imparfaites et essaie de faire au mieux. C’est utile pour du diagnostic, beaucoup moins pour décider si une entrée utilisateur est sûre. En code neuf, je m’en sers comme d’un outil de lecture, pas comme d’un garde-fou.
Si je veux ensuite analyser les paramètres, je passe souvent par parse_str(), mais avec une vraie prudence: il transforme la chaîne de requête en tableau et les valeurs sont déjà décodées. Il faut aussi retenir qu’en PHP récent, le second paramètre est obligatoire, donc pas de vieille habitude consistant à injecter des variables dans le scope courant. Une fois cette structure visible, la vraie question devient simple: comment reconstruire l’URL sans casser les paramètres.
Construire une chaîne de requête sans bricolage
Pour créer une URL avec des paramètres, je préfère presque toujours http_build_query(). La fonction prend un tableau ou un objet et génère une chaîne de requête encodée correctement. C’est plus fiable que de concaténer des morceaux à la main, surtout dès qu’il y a des tableaux imbriqués, des valeurs avec espaces ou des paramètres optionnels.
Le point qui surprend souvent: par défaut, l’encodage suit RFC 1738, donc les espaces deviennent des signes +. Si je veux un rendu plus strict de type RFC 3986, j’utilise le quatrième paramètre avec PHP_QUERY_RFC3986 et les espaces passent en %20. Dans une API moderne ou un lien destiné à être relu par plusieurs systèmes, ce détail compte.
2,
'sort' => 'price asc',
'tags' => ['php', 'web'],
];
$query = http_build_query($params, '', '&', PHP_QUERY_RFC3986);
echo '/articles?' . $query;
Le résultat est propre, lisible et reproductible. Je note aussi que http_build_query() respecte les propriétés publiques d’un objet et gère un séparateur d’arguments configurable. En pratique, ça évite beaucoup d’erreurs classiques: oublier un &, mal gérer un tableau, ou produire une URL différente selon l’ordre d’écriture des lignes. La suite logique, c’est de comprendre quel encodeur employer pour chaque partie de l’adresse.
Encoder le bon morceau au bon moment
Une erreur fréquente consiste à encoder une URL entière d’un seul bloc. En réalité, chaque portion obéit à sa propre logique. Le chemin, la requête, le fragment et parfois les identifiants intégrés dans l’URL ne se traitent pas de la même manière. C’est précisément là que rawurlencode() et urlencode() doivent être distingués.
| Partie de l’URL | Fonction conseillée | Usage correct | Piège courant |
|---|---|---|---|
| Segment de chemin | rawurlencode() |
Nom de dossier, slug, nom de fichier | Encodage du chemin complet, qui casse les /
|
| Valeur de requête |
http_build_query() ou urlencode()
|
Paramètre GET, filtre, pagination | Confondre + et %20
|
| Fragment | Encodage ciblé si besoin | Ancre de section, état de navigation | L’ajouter avant la requête |
| Hôte | Pas d’encodage brut | Domaine, sous-domaine, IPv6 | Appliquer rawurlencode() à tout le bloc |
Je m’en tiens à une règle simple: le chemin s’encode par segments, la requête se reconstruit comme une requête, et l’hôte ne se trafique pas à la main. Si un nom de fichier contient un espace, rawurlencode() donne généralement le comportement attendu avec %20. Si je construis une URL de recherche ou de filtrage, je laisse http_build_query() faire le travail.
'php url',
'lang' => 'fr',
], '', '&', PHP_QUERY_RFC3986);
echo $path . '?' . $search;
Le bon encodeur dépend donc du contexte, pas du mot « URL » lui-même. Et c’est justement ce contexte qui devient critique au moment de valider une entrée utilisateur ou une redirection.
Valider sans confondre forme et sécurité
Pour un premier filtre, filter_var($url, FILTER_VALIDATE_URL) reste utile. Il permet de rejeter rapidement des chaînes qui ne ressemblent pas à des URL. Mais je ne lui confie jamais la sécurité d’un flux à lui seul. D’abord parce qu’il ne valide pas la politique métier du projet. Ensuite parce qu’il y a des limites concrètes: le filtre fonctionne sur des URL ASCII, donc les domaines internationalisés peuvent être rejetés, et un schéma valide n’est pas forcément le bon schéma pour votre cas d’usage.
Le manuel PHP rappelle aussi qu’une URL valide ne doit pas obligatoirement commencer par http://. C’est un détail important: si je n’attends que du HTTPS, je dois le vérifier explicitement. Pour une redirection, un webhook ou un lien de callback, je combine donc trois niveaux: validation syntaxique, contrôle du schéma, puis allow-list d’hôtes autorisés.
Je préfère aussi éviter de bâtir une logique de sécurité sur parse_url() seul, car ce n’est pas un validateur et les parsers n’interprètent pas tous les cas tordus de la même façon. Pour du code neuf, le manuel de PHP pointe même vers des classes d’URL plus strictes, ce qui confirme une chose: dès qu’il y a un enjeu de sécurité, le simple découpage ne suffit pas. Reste à voir les erreurs de terrain qui reviennent malgré tout dans les projets web.
Les erreurs qui reviennent en production
Quand une URL casse en production, ce n’est presque jamais à cause d’un seul gros bug. Ce sont plutôt des petites fautes répétées qui se combinent. La première, que je vois souvent, c’est le double encodage: on encode un segment, puis on réencode l’URL entière, et les caractères deviennent illisibles. La deuxième, c’est l’ajout manuel de paramètres alors qu’il existe déjà une requête en place. On finit alors avec des liens du type ?name=Paul?page=2, ce qui est faux dès la première navigation.
- Encoder un chemin complet au lieu d’encoder chaque segment séparément.
- Oublier le fragment
#...en reconstruisant l’URL. - Utiliser
FILTER_VALIDATE_URLsur une route interne relative, alors que ce n’est pas son rôle. - Supposer que plusieurs clés identiques dans une query string seront conservées telles quelles.
- Employer
parse_str()sans penser aux tableaux, aux noms de clés et au décodage déjà appliqué.
Sur un site de contenu, ces détails apparaissent vite: pagination, filtres, partage social, UTM, redirections après connexion. En français comme ailleurs, les slugs avec espaces ou accents nécessitent aussi une politique claire. Je conseille des slugs propres dès la génération, puis un encodage explicite à l’affichage ou à la requête. C’est souvent ce petit degré de rigueur qui fait la différence entre un lien qui marche sur le papier et un lien robuste en production.
La méthode simple que j’applique sur un projet web
Si je devais résumer ma façon de travailler, je dirais qu’elle tient en quatre gestes: découper, transformer, reconstruire, puis contrôler. Je commence par isoler les composants utiles avec parse_url(), je modifie seulement ce qui doit l’être, je reconstruis la chaîne de requête avec http_build_query(), puis je valide le résultat selon le contexte réel du projet.
Cette méthode marche bien parce qu’elle évite les raccourcis séduisants mais fragiles. Elle me permet aussi de distinguer les liens internes, les URL externes, les redirections et les callbacks, qui n’ont pas les mêmes exigences. Dans un projet moderne, je garde donc une logique simple: utiliser les fonctions natives pour le format, appliquer une allow-list pour la confiance, et réserver les traitements spéciaux aux cas qui les méritent vraiment.
Dans la plupart des cas, c’est suffisant pour gérer des URL propres, lisibles et prévisibles en PHP. Et quand le projet devient plus exigeant, je passe à des outils de parsing plus stricts plutôt que de forcer les fonctions de base à faire un travail pour lequel elles n’ont jamais été conçues.