
Récupérer l’URL courante en PHP paraît simple, mais la réponse dépend vite de ce que l’on appelle exactement « URL » : l’adresse complète, le chemin, la chaîne de requête ou seulement le domaine. Dans un projet web réel, je m’en sers pour générer un lien canonique, préparer une redirection, tracer une page ou afficher un partage propre. La requête php récupérer url renvoie donc à un besoin très concret: reconstruire l’adresse correcte sans se tromper sur le schéma, le port ou les paramètres.
Les points à garder en tête avant d’écrire votre code
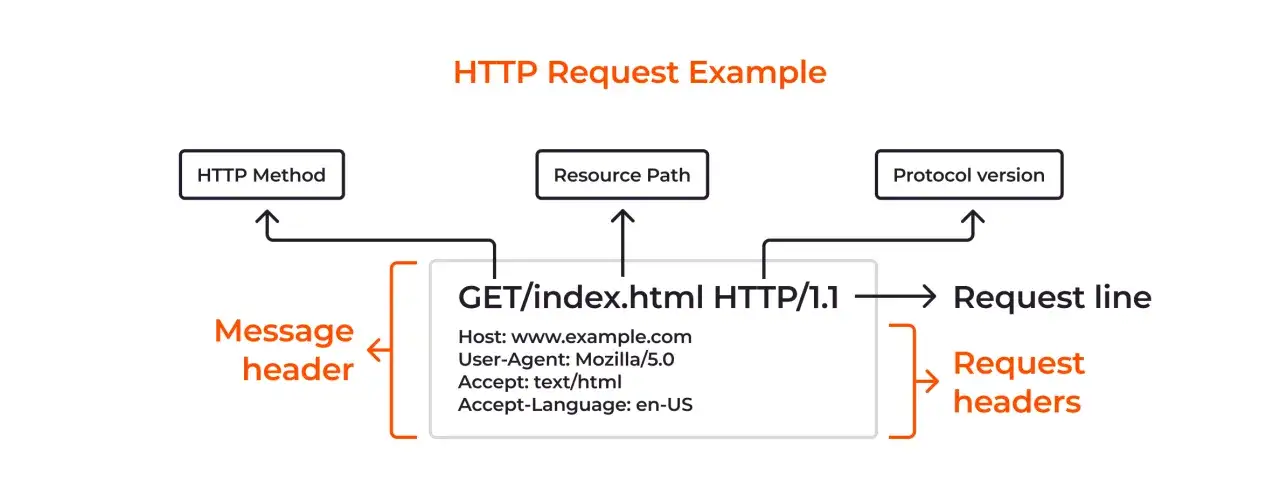
- `$_SERVER['REQUEST_URI']` donne le chemin demandé et la chaîne de requête, mais pas le domaine.
- Pour reconstituer l’adresse complète, on combine généralement le schéma, `HTTP_HOST` et `REQUEST_URI`.
- `PHP_SELF` fonctionne dans des cas simples, mais je le considère moins fiable pour produire une URL canonique.
- `parse_url()` sert surtout à découper une URL déjà connue en morceaux exploitables.
- Derrière un proxy ou en HTTPS forcé, le schéma peut être trompeur si l’infrastructure n’est pas prise en compte.
Récupérer l’URL complète sans se tromper
Si je dois obtenir l’adresse complète de la page active, je pars d’une reconstruction simple: le schéma, le nom d’hôte et l’URI de la requête. C’est la méthode la plus lisible et la plus courante en PHP pur.
Cette approche fonctionne bien parce qu’elle sépare les responsabilités: `HTTP_HOST` fournit le domaine, `REQUEST_URI` fournit le chemin et les paramètres, et le schéma est déduit de la connexion HTTPS. Dans beaucoup de projets, c’est largement suffisant pour afficher une URL complète, générer un lien de partage ou journaliser la page consultée.
Je garde toutefois une réserve importante: si l’application est derrière un reverse proxy, un CDN ou un load balancer, le schéma vu par PHP n’est pas toujours le schéma réellement utilisé par le visiteur. C’est précisément le genre de détail qui peut casser une redirection ou produire une URL canonique incorrecte. Pour ce type de contexte, il faut regarder l’infrastructure avant d’accuser le code.
Une fois cette base posée, il devient plus simple de comprendre ce que chaque variable serveur apporte réellement.
Comprendre ce que renvoient les variables serveur
Le manuel PHP rappelle que $_SERVER dépend du serveur web et que toutes les entrées ne sont pas garanties partout. En clair, ces variables sont pratiques, mais elles ne sont pas toutes équivalentes ni universellement présentes.
| Variable | Contenu | Usage le plus utile | Limite principale |
|---|---|---|---|
REQUEST_URI |
Chemin demandé et chaîne de requête | Reconstruire l’URL à partir de la requête | N’inclut ni le schéma ni le domaine |
HTTP_HOST |
Nom d’hôte envoyé par le client, parfois avec le port | Former la partie domaine de l’URL | Depend de l’en-tête Host et du contexte réseau |
PHP_SELF |
Chemin du script exécuté | Cas simples, formulaires internes | Peut être moins fiable pour une URL canonique |
SCRIPT_NAME |
Chemin du script sans la query string | Identifier le point d’entrée PHP | Ne représente pas l’adresse complète |
QUERY_STRING |
Paramètres bruts après le ?
|
Récupérer uniquement les paramètres | Ne contient pas le chemin |
Ce tableau résume l’essentiel: si vous voulez l’adresse complète, REQUEST_URI est la pièce centrale; si vous voulez seulement le domaine, HTTP_HOST est la bonne source; si vous voulez les paramètres seuls, QUERY_STRING suffit souvent.
Quand je veux afficher ou comparer l’adresse courante, je préfère aussi éviter PHP_SELF comme réflexe automatique. Il reste utile dans certains formulaires ou scripts très simples, mais pour un lien canonique, un breadcrumb ou une redirection, je trouve REQUEST_URI plus clair et plus prévisible.
Le point suivant compte beaucoup en production: la présence d’un proxy, d’un port non standard ou d’une terminaison HTTPS en amont change la manière de lire ces variables.
Gérer HTTPS, les ports et les proxys sans casser l’adresse
En local, tout semble simple. En production, ça se complique vite: un site peut être servi en HTTPS au navigateur, tout en apparaissant en HTTP pour PHP si un proxy termine le chiffrement avant d’acheminer la requête vers l’application. C’est là que les approximations commencent à coûter du temps.
Voici les cas que je vérifie systématiquement:
-
HTTPS terminé en amont : PHP peut voir
HTTPSà vide même si le visiteur est bien en HTTPS. -
Port non standard :
HTTP_HOSTpeut inclure:8080,:8443ou un autre port utile en dev. - Domaine canonique : si votre site doit toujours répondre sur un seul domaine, je préfère parfois une configuration applicative explicite plutôt que le host brut de la requête.
- Environnement CLI : dans une tâche cron ou un script lancé en ligne de commande, ces variables n’ont pas le même sens, voire sont absentes.
Dans une application moderne, je considère le schéma comme une donnée d’infrastructure, pas comme une simple chaîne à concaténer. C’est encore plus vrai si vous utilisez Symfony, Laravel ou un autre framework: l’objet de requête y est souvent mieux calibré pour savoir si l’URL perçue est réellement celle que voit l’utilisateur.
Une fois cette couche de contexte maîtrisée, on peut passer à une manipulation plus fine: extraire seulement une partie de l’adresse au lieu de tout reconstruire à la main.
Découper l’adresse avec parse_url quand il faut seulement un morceau
Le manuel PHP décrit parse_url() comme une fonction qui découpe une URL en composants. C’est exactement ce que je lui demande lorsque j’ai déjà une adresse complète et que je veux isoler le chemin, la requête ou le fragment.
Ce découpage est plus propre que des manipulations artisanales sur des chaînes. Si je veux juste le chemin de la page courante, je peux par exemple faire: parse_url($_SERVER['REQUEST_URI'], PHP_URL_PATH). Si je veux les paramètres, je garde la query string et je la transforme ensuite en tableau avec parse_str().
Je note aussi une nuance utile en 2026: si votre base tourne déjà en PHP 8.5, l’extension URI apporte une API plus moderne pour analyser et modifier les URL selon les standards RFC 3986 et WHATWG. Pour un projet neuf qui manipule beaucoup d’adresses, c’est intéressant. Pour un besoin simple comme récupérer l’URL courante, parse_url() reste néanmoins une solution parfaitement acceptable et très répandue.
Ce découpage devient surtout utile lorsqu’on veut éviter les erreurs classiques que je vois encore trop souvent dans les projets web.
Les erreurs que je vois le plus souvent
-
Confondre URL complète et chemin :
REQUEST_URIne donne pas le domaine, donc on ne peut pas l’afficher seule comme adresse absolue. -
Utiliser
PHP_SELFpour tout : cela marche parfois, mais ce n’est pas mon choix pour une URL canonique ou une redirection soignée. - Oublier la query string : si vous reconstruisez l’URL à la main, vous pouvez perdre des paramètres importants.
- Faire confiance au host sans réflexion : le host de la requête est pratique, mais il ne remplace pas une stratégie de domaine maîtrisée.
- Négliger le contexte d’exécution : le code qui fonctionne dans le navigateur peut renvoyer autre chose en CLI, en test automatisé ou via un worker.
- Réutiliser l’URL courante pour rediriger sans contrôle : dès qu’il y a une entrée utilisateur dans la boucle, je vérifie la logique pour éviter les redirections ouvertes ou les boucles inutiles.
Le vrai sujet n’est donc pas de trouver une formule magique, mais de choisir la variable adaptée à l’usage. Quand je fais ce tri dès le départ, le code devient plus lisible et les bugs réseau se raréfient.
La règle simple que j’applique en production
Quand je dois aller vite sans sacrifier la fiabilité, j’utilise cette logique:
-
URL complète : je combine schéma,
HTTP_HOSTetREQUEST_URI. -
Chemin seul : je pars de
REQUEST_URIpuis j’extraisPHP_URL_PATH. -
Paramètres seuls : je lis
QUERY_STRINGou je découpe la query avecparse_url(). -
Projet avec framework : je préfère l’objet de requête fourni par le framework plutôt qu’un bricolage sur
$_SERVER.
Cette règle tient bien dans les projets de contenu, les back-offices et les applications métier. Elle évite surtout de mélanger trois besoins différents sous une seule formule approximative. C’est exactement ce qui rend la récupération de l’URL courante en PHP plus robuste qu’il n’y paraît au premier coup d’œil.
En pratique, le bon réflexe est de choisir d’abord ce que vous voulez obtenir, puis seulement la variable à utiliser. C’est cette discipline simple qui rend le code plus stable, plus lisible et plus facile à maintenir quand le projet grandit.