")
L’essentiel à garder en tête avant de choisir un verbe HTTP
- GET sert à lire, filtrer, paginer et afficher une ressource sans modifier l’état côté serveur.
- POST sert à envoyer des données, créer une ressource ou déclencher une action avec effet de bord.
- Les paramètres en GET passent dans l’URL, ceux du POST vont dans le corps de la requête.
- GET se prête naturellement au cache, au partage d’URL et aux retours en arrière du navigateur.
- POST n’est pas une protection de sécurité en soi: seule une connexion chiffrée et une validation serveur font le travail.
- Si l’opération doit être répétable sans effet imprévu, je regarde d’abord GET ou un autre verbe idempotent, pas POST par automatisme.
Ce que GET et POST font réellement
Dans le modèle HTTP, GET demande une représentation d’une ressource. Autrement dit, le client veut lire quelque chose: une page, une liste de produits, un résultat de recherche, un article, une donnée de profil déjà existante. POST, lui, envoie une entité vers le serveur pour traiter une soumission, créer un élément ou provoquer une action.
| Critère | GET | POST | Impact concret |
|---|---|---|---|
| Rôle principal | Récupérer des données | Envoyer des données | GET sert au lecture seule, POST à l’échange ou à la mutation |
| Emplacement des paramètres | URL, généralement dans la query string | Corps de la requête | La lisibilité et le partage ne donnent pas le même résultat |
| Effet sur l’état | Pas censé modifier l’état | Souvent associé à une modification | Le serveur ne doit pas attendre la même sémantique |
| Mise en cache | Naturellement compatible | Possible, mais moins fréquente | Les CDN et les navigateurs exploitent plus facilement GET |
| Partage et historique | Très pratique | Peu adapté | Une URL GET se copie, se marque et se retrouve facilement |
| Idempotence | Oui, en principe | Non garantie | Une répétition de GET ne doit pas changer le résultat attendu |
Le point que beaucoup de débutants sous-estiment, c’est la sémantique. GET ne signifie pas seulement “requête avec paramètres”, et POST ne signifie pas seulement “requête avec formulaire”. Le verbe dit au serveur et aux intermédiaires comment interpréter l’intention. C’est cette intention qui fait la différence quand le navigateur recharge une page, quand un proxy met en cache, ou quand un robot explore votre site.
Quand GET est le meilleur choix
Je choisis GET dès qu’il s’agit de lire un état plutôt que de le modifier. C’est le cas pour une recherche, un filtre, un tri, une pagination ou une page de détail. Une URL GET reste partageable, reproductible et souvent plus compréhensible pour un utilisateur ou pour un outil de monitoring.
- Recherche et filtres : une page de catalogue avec `?q=ordinateur&tri=prix` se partage facilement, ce qui est précieux sur un site e-commerce ou un annuaire technique.
- Pagination : `?page=4` ou `?offset=60` garde l’état visible dans l’URL, ce qui simplifie le retour arrière et la reprise de navigation.
- Ressources publiques : article, fiche produit, documentation, flux public, résultat de lecture API.
- Prévisualisation non destructive : calcul, simulation, affichage d’un devis sans validation finale ni création d’objet.
Il y a toutefois une limite nette: si les paramètres deviennent trop sensibles, trop volumineux ou trop complexes, GET perd en confort. Une URL doit rester lisible et exploitable. Dès que la requête transporte une vraie charge métier, POST devient souvent plus adapté. C’est précisément là que le choix bascule.
Quand POST devient indispensable
Je passe à POST quand la requête crée, soumet ou déclenche quelque chose. C’est le bon verbe pour un formulaire d’inscription, une commande, un envoi de message, une soumission de commentaire ou un appel d’API qui crée un nouvel enregistrement.
- Création d’une ressource : un compte, une commande, un ticket support, un brouillon sauvegardé côté serveur.
- Actions avec effet de bord : envoyer un e-mail, lancer un paiement, déclencher une tâche, réinitialiser un mot de passe.
- Payload structuré : JSON complexe, tableau imbriqué, métadonnées multiples, objet de formulaire riche.
- Upload de fichiers : dès qu’il y a un fichier ou un contenu plus lourd à transmettre, POST est le choix naturel.
- Connexion et authentification : souvent en POST, parce qu’on transmet des données de formulaire sans exposer la structure dans l’URL.
J’insiste sur un point qui évite beaucoup de malentendus: POST n’est pas un coffre-fort. Il masque les données dans le corps de la requête, mais ne les chiffre pas. La confidentialité vient d’abord de HTTPS, puis de la validation côté serveur, de la gestion des journaux et de la protection contre les abus. Si l’on envoie un secret, il faut penser au transport, aux logs et au stockage, pas seulement à la méthode.
Les différences techniques qui changent le comportement réel
La théorie est simple; l’expérience utilisateur et l’architecture ne le sont pas toujours. Ce sont les détails autour du navigateur, du cache et des intermédiaires réseau qui rendent le sujet intéressant. Dans un projet web, c’est souvent là que la mauvaise méthode devient visible.
- Cache : GET est conçu pour être cacheable de manière naturelle. POST peut l’être dans certains cas, mais ce n’est pas le comportement le plus courant et il faut une configuration explicite.
- Historique et bookmark : une URL GET peut être enregistrée, partagée et retrouvée facilement. Un POST ne donne pas ce confort.
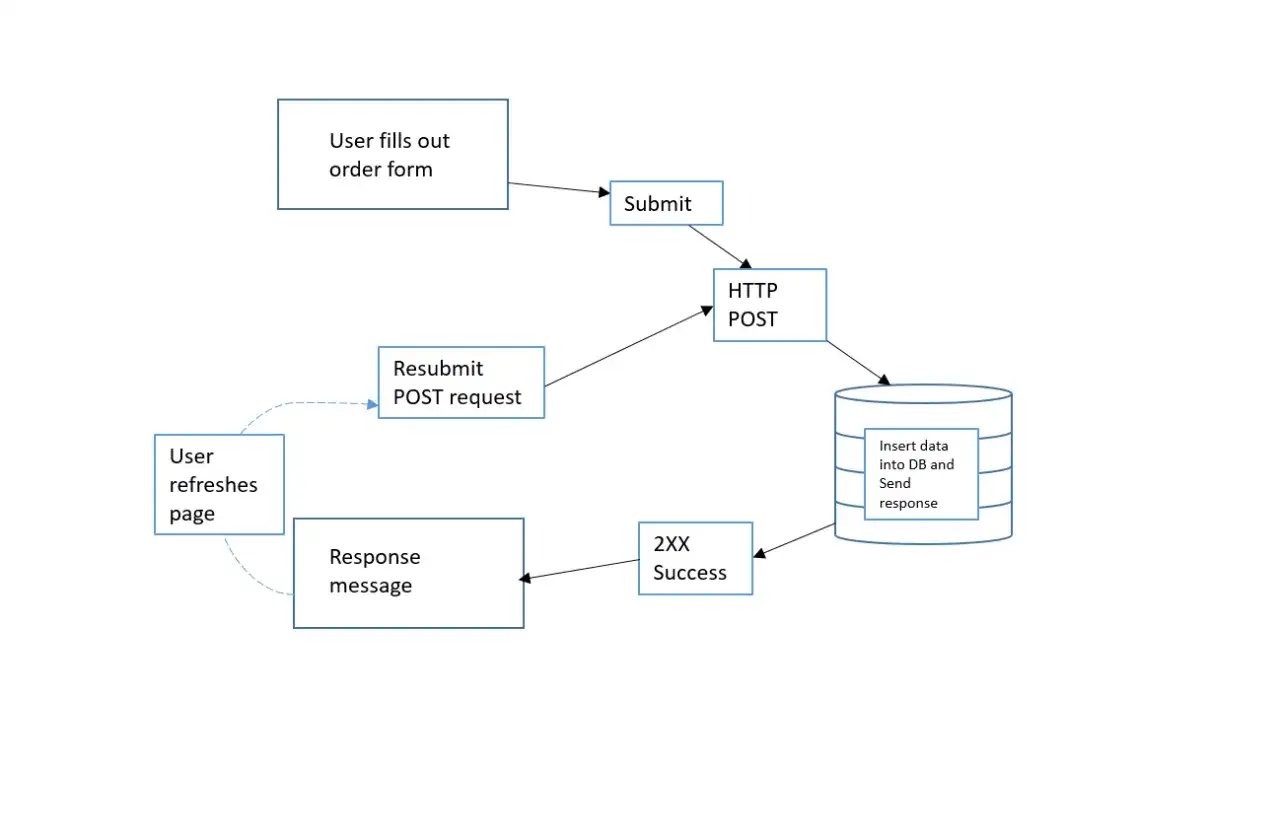
- Rafraîchissement de page : recharger une page GET est généralement neutre. Rejouer un POST peut recréer une commande, renvoyer un formulaire ou dupliquer une opération.
- Idempotence : GET est censé être idempotent, donc répétable sans effet supplémentaire. POST ne garantit pas cette propriété.
- Lisibilité des logs : les paramètres GET apparaissent souvent dans les journaux et outils de monitoring. C’est pratique pour diagnostiquer, mais mauvais pour les données sensibles.
- Limites pratiques : GET supporte très bien les paramètres légers à modérés, mais une URL trop longue devient pénible à maintenir et parfois limitée par certains composants de la chaîne.
Le mot important ici est pratique. En théorie, HTTP est élégant. En production, il faut composer avec les navigateurs, les proxies, les CDN, les logs applicatifs et les habitudes d’outillage. Une même décision peut être excellente pour le cache et mauvaise pour la confidentialité, ou l’inverse. C’est pour cela que je ne décide jamais uniquement sur la syntaxe de la requête.
Les erreurs que je vois le plus souvent en développement web
Les mauvaises habitudes reviennent souvent aux mêmes endroits. Elles ne cassent pas toujours l’application immédiatement, mais elles la rendent moins fiable, moins claire et parfois plus risquée.
- Utiliser POST pour une simple lecture : une recherche ou un filtre sous POST perd en ergonomie et en partage d’URL sans gain réel.
- Utiliser GET pour une action destructive : supprimer, valider, payer ou modifier via GET expose à des rechargements et à des comportements involontaires.
- Confondre POST et sécurité : masquer des données dans le corps n’empêche ni l’interception sur une connexion non chiffrée ni l’exposition dans certains outils internes.
- Mettre des secrets dans la query string : jetons, mots de passe temporaires ou données personnelles ne devraient pas finir dans l’URL.
- Ignorer les doublons de soumission : si un utilisateur double-clique ou si le client réessaie, un POST non protégé peut créer deux fois la même chose.
- Choisir la méthode sans penser au contrat métier : le verbe HTTP doit refléter l’intention, pas seulement la facilité de mise en œuvre dans le framework.
Quand je corrige ce genre de dérive, je regarde toujours la même question: que se passe-t-il si la requête est répétée, partagée ou enregistrée? Si la réponse pose problème, le verbe choisi est probablement le mauvais, ou alors le contrat de l’API doit être mieux défini.
Comment trancher rapidement sans casser l’architecture
Pour décider vite, j’utilise une grille simple. Elle évite les discussions théoriques interminables et donne un choix cohérent dès la première itération.
- Est-ce que l’opération lit seulement une donnée? Oui: partez sur GET.
- Est-ce que l’opération crée, envoie ou modifie quelque chose? Oui: partez sur POST.
- Dois-je pouvoir partager l’URL telle quelle? Si oui, GET est presque toujours meilleur.
- Le payload est-il structuré, long ou peu adapté à une URL? POST est plus confortable.
- Une répétition de la même requête doit-elle être sans risque? Si oui, évitez POST par automatisme et vérifiez si un verbe idempotent serait plus juste.
Dans un site de contenu ou une interface orientée recherche, je garde souvent GET pour tout ce qui est navigation, tri et filtrage. Dans une application métier, POST prend le relais dès qu’on passe dans l’action: création, validation, transfert, envoi. Cette séparation améliore la lisibilité technique et réduit les surprises côté utilisateur.
Le réflexe simple que j’applique avant de coder un endpoint
Avant de créer une route, je vérifie trois choses: est-ce que je lis, est-ce que je transforme, est-ce que je déclenche? Lire appelle GET. Transformer ou déclencher appelle POST, sauf cas particulier où un autre verbe HTTP serait plus juste. Ce réflexe paraît basique, mais il évite beaucoup de contresens dans les API comme dans les formulaires.
Si je devais résumer la règle de travail la plus utile, ce serait celle-ci: GET pour l’état visible et partageable, POST pour l’action et l’envoi. Ensuite seulement, je traite les détails qui comptent vraiment en production: HTTPS, validation serveur, anti-CSRF, gestion des doublons, et cohérence des logs. C’est cette discipline qui fait la différence entre une implémentation “qui marche” et une implémentation propre, durable et facile à faire évoluer.