
La redirection PHP est l’un des outils les plus utiles quand il faut déplacer un utilisateur sans casser le parcours, que ce soit après un formulaire, lors d’une migration d’URL ou pour imposer une règle d’accès. Bien exécutée, elle reste invisible et propre; mal choisie, elle crée des boucles, des erreurs de méthode ou des signaux SEO contradictoires. Je vais donc aller droit au but: comment la faire correctement, quel code HTTP utiliser et quels pièges éviter en production.
Les points essentiels à retenir avant d’implémenter une redirection
- La mécanique repose sur l’en-tête Location, pas sur un simple changement visuel côté navigateur.
- Sans code explicite, PHP envoie généralement un 302; il faut donc choisir volontairement le bon statut.
- Après un POST, le plus propre est souvent 303 si l’objectif est d’afficher une page de confirmation en
GET. - 301 et 308 servent aux déplacements permanents; 302 et 307 aux déplacements temporaires.
- exit; juste après la redirection évite que le script continue d’écrire une réponse incohérente.
- Si la destination dépend d’un paramètre utilisateur, il faut la filtrer avec une liste blanche pour éviter une redirection ouverte.
Ce que fait vraiment une redirection côté serveur
Une redirection n’est pas un tour de passe-passe visuel. Le serveur répond d’abord avec un statut HTTP et un en-tête Location, puis le navigateur relance automatiquement une autre requête vers la nouvelle adresse. Autrement dit, on ne “déplace” pas la page dans le DOM: on indique au client où aller, et c’est cette nouvelle requête qui charge le contenu final.
C’est précisément pour cela que la redirection côté serveur est plus fiable qu’une solution JavaScript quand il faut gérer un flux critique: connexion, changement d’URL, maintenance, ou consolidation d’anciennes pages. Elle est aussi plus lisible pour les robots d’indexation et pour les outils d’analyse réseau. Une fois ce mécanisme compris, la vraie question devient: à quel moment PHP doit-il s’en charger, et à quel moment faut-il plutôt laisser le serveur web faire le travail?
Quand la redirection PHP est la bonne solution
Je privilégie une redirection en PHP quand la décision dépend du contexte de la requête: état de session, rôle de l’utilisateur, résultat d’un formulaire, langue choisie, ou contenu déjà inspecté par l’application. Dans ces cas-là, la logique vit naturellement dans le code applicatif.
En revanche, si la règle est globale et stable, je préfère souvent la traiter au niveau du serveur web ou de l’edge réseau. Forcer http vers https, passer de www à la version canonique du domaine, ou rediriger un ancien ensemble d’URL vers un nouveau chemin n’a pas besoin de charger toute l’application PHP à chaque requête. Cette distinction change la performance, la maintenabilité et parfois même le comportement du cache.
- Cas adaptés à PHP: après une connexion réussie, après validation d’un formulaire, selon le pays ou la langue détectés, selon les droits de l’utilisateur.
- Cas souvent mieux gérés ailleurs: redirection de domaine, canonicalisation globale, migrations massives, forçage HTTPS à l’échelle du site.
Cette séparation évite beaucoup de code inutile. Et une fois qu’on sait où placer la logique, il devient plus simple de choisir le bon statut HTTP, ce qui est le point le plus souvent mal traité.
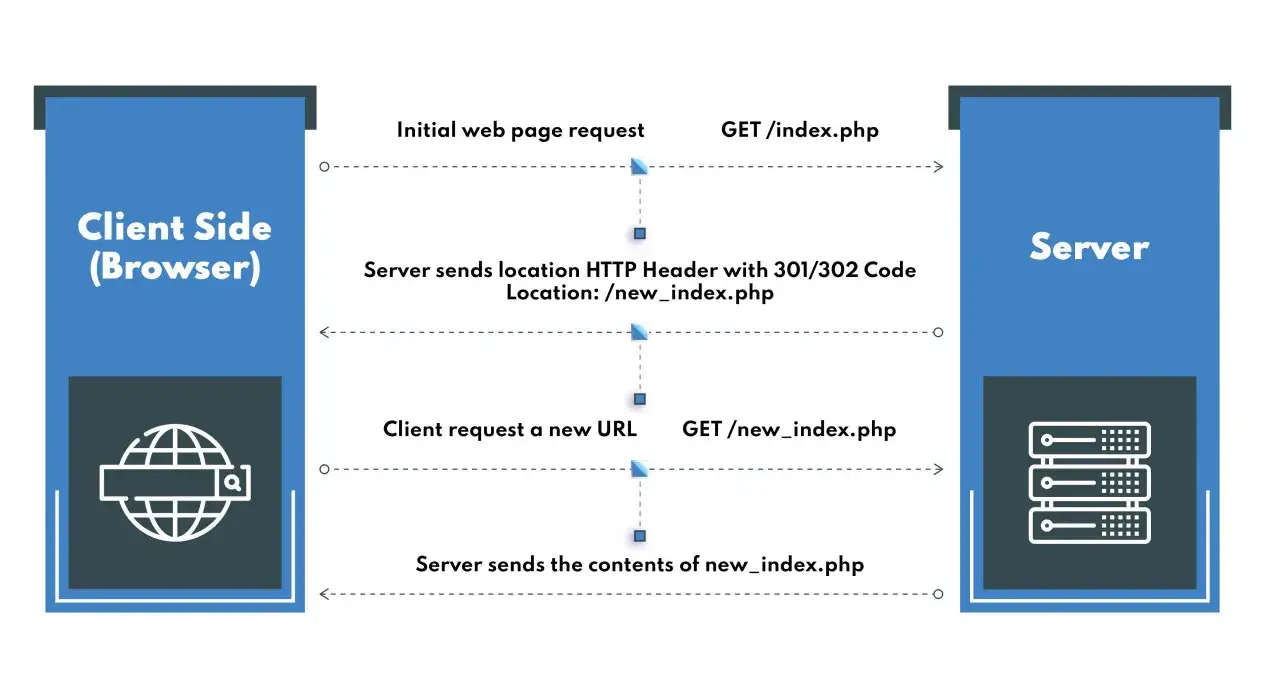
Choisir le bon code HTTP pour éviter les mauvais effets
Le statut HTTP n’est pas décoratif. Il indique au navigateur, aux caches et aux moteurs comment interpréter le déplacement. Sur un projet sérieux, je ne laisse pas ce choix au hasard, parce qu’un mauvais code peut provoquer une mauvaise indexation, une répétition de requête ou un comportement étrange après un formulaire.
| Code | Usage principal | Effet sur la méthode | Ce que je fais en pratique |
|---|---|---|---|
| 301 | Déplacement permanent | Le client peut convertir la requête en GET
|
Je l’utilise pour une URL devenue définitive, avec une nouvelle adresse canonique |
| 302 | Déplacement temporaire | Le comportement historique est souple; souvent traité comme un passage temporaire | Je le garde pour une redirection provisoire ou une règle de transition |
| 303 | Page de résultat après POST
|
Le navigateur repart en GET
|
Je le choisis après traitement d’un formulaire pour éviter la re-soumission au rafraîchissement |
| 307 | Déplacement temporaire avec méthode conservée | La méthode et le corps sont conservés | Je l’utilise quand la requête doit être rejouée à l’identique ailleurs |
| 308 | Déplacement permanent avec méthode conservée | La méthode et le corps sont conservés | Je le préfère à 301 quand je veux un permanent sans perte de méthode |
Le point pratique à retenir est simple: 301 et 308 parlent d’un changement durable, 302 et 307 d’un passage provisoire, et 303 est souvent la meilleure réponse après un formulaire qui doit déboucher sur une page de confirmation. En 2026, je considère encore ce dernier point comme l’un des plus sous-estimés par les débutants. Une fois le code choisi, il reste à écrire une redirection propre et lisible.
Écrire une redirection fiable en PHP
La forme la plus simple est aussi la plus robuste: envoyer l’en-tête, puis arrêter le script. Je préfère garder cette règle partout, même quand le code semble trivial, parce qu’elle élimine une grande partie des bugs de fin de requête.
Ce schéma est particulièrement adapté après un formulaire POST. L’utilisateur arrive sur une page de confirmation en GET, et un simple rafraîchissement ne rejoue pas la soumission. Pour une redirection permanente vers une nouvelle page, la logique est identique, mais avec un autre statut:
Si tu dois conserver la méthode initiale pour une migration temporaire ou un renvoi technique, le statut change encore. Je le souligne parce que beaucoup de code de production mélange 302, 301 et 303 sans intention claire, alors que la différence est précisément ce qui rend le comportement prévisible.
Un seul point ne doit jamais être oublié: aucune sortie ne doit précéder l’appel à header(). Pas d’espace, pas d’echo, pas de HTML déjà envoyé. Sur un vieux projet, j’utilise parfois la mise en tampon de sortie pour m’en sortir, mais je la considère comme un filet de sécurité, pas comme une excuse pour laisser un contrôle flou de la réponse. Le sujet suivant est tout aussi important: la sécurité de la destination.
Protéger les redirections dynamiques
Dès qu’une destination vient d’un paramètre, d’un cookie ou d’une valeur de base de données, il faut vérifier ce qu’on autorise à passer. Sinon, on ouvre la porte à une redirection ouverte: un attaquant peut injecter une cible externe et transformer ton site en relais de phishing. C’est un problème classique, et il est évitable avec une règle simple: ne jamais rediriger vers une valeur brute sans validation.
'/compte/profil',
'factures' => '/compte/factures',
'accueil' => '/tableau-de-bord',
];
$key = $_GET['next'] ?? 'accueil';
$destination = $targets[$key] ?? '/tableau-de-bord';
header('Location: ' . $destination, true, 302);
exit;
Ici, la destination est choisie dans une liste blanche, pas dans une chaîne libre. C’est plus rigide, mais c’est précisément ce qu’il faut. Si tu dois laisser l’utilisateur choisir une page de retour, limite ce choix à des chemins internes connus, et évite les valeurs qui commencent par http:// ou https://. Dans un contexte de connexion, de checkout ou de zone privée, cette précaution vaut largement les quelques lignes de code supplémentaires. Ensuite, il reste à éviter les erreurs les plus banales, celles qui font croire que “la redirection ne marche pas”.
Les erreurs que je vois le plus souvent
- Du contenu a déjà été envoyé avant l’en-tête: la redirection échoue ou génère un comportement incohérent.
-
Le script continue après le transfert: sans
exit;, la page peut encore produire une réponse ou lancer d’autres traitements. -
Le mauvais code HTTP est utilisé: un
302après un formulaire n’exprime pas la même intention qu’un303. - Une boucle de redirection se crée entre deux pages qui se renvoient l’une vers l’autre.
- Une cible relative mal pensée pointe vers le mauvais répertoire parce que le chemin est calculé depuis le mauvais niveau.
- Une ancienne règle permanente reste en cache navigateur ou proxy alors qu’elle a été modifiée trop tard.
Pour diagnostiquer vite, je commence par les outils réseau du navigateur: code de réponse, en-tête Location, nombre de sauts et page finale. Si le code ne correspond pas à l’intention, je corrige d’abord le statut, ensuite le chemin, puis l’ordre d’exécution. Cette méthode simple évite de chercher un bug imaginaire dans le navigateur alors que le problème vient souvent du script lui-même. Reste une dernière question pratique: qu’est-ce que je valide systématiquement avant de livrer?
Les réflexes que j’applique avant de mettre une redirection en production
Avant de considérer une redirection comme terminée, je vérifie trois choses: l’intention, le statut et la sécurité. Si ces trois points sont alignés, le comportement est généralement solide et durable.
- Je confirme que la redirection est bien permanente ou temporaire, sans ambiguïté.
- Je m’assure que le bon code HTTP est envoyé, en particulier après les formulaires.
- Je teste le chemin final en navigation normale et en rafraîchissement de page.
- Je vérifie qu’aucune sortie HTML ne précède l’appel à
header(). - Je bloque toute destination qui ne fait pas partie d’une liste autorisée.
- Je garde une seule étape de redirection quand c’est possible, pour éviter les chaînes inutiles.
En pratique, une bonne redirection n’attire pas l’attention. Elle est rapide, lisible, stable, et elle envoie le signal attendu au navigateur comme aux moteurs. C’est exactement ce qu’on cherche dans un développement web propre: une logique simple, assumée, et suffisamment précise pour ne pas devenir une source de dette technique plus tard.