
Créer un ensemble en Java semble simple, mais le choix de la bonne implémentation change vite la qualité du code. Entre les doublons, l’ordre d’itération, le tri et l’immuabilité, un mauvais choix se paie ensuite en tests fragiles, en affichage incohérent ou en performances inutiles. Ici, je vais aller droit au but: comment créer un Set proprement, quelle variante choisir selon le besoin, et quels pièges éviter.
Je passerai aussi en revue les cas les plus fréquents en projet réel: partir d’une liste, d’un flux, d’un tableau ou d’un ensemble de valeurs figées. Le but est de donner un réflexe fiable, pas une recette unique qui marche seulement dans les exemples de cours.
L’essentiel à retenir avant de créer un set en Java
-
Un
Setélimine les doublons automatiquement: deux éléments égaux ne cohabitent pas. -
HashSetreste le choix par défaut si l’ordre n’a aucune importance. -
LinkedHashSetgarde l’ordre d’insertion, ce qui aide pour les logs, les exports ou l’UI. -
TreeSettrie les éléments, mais coûte plus cher qu’unHashSet. -
Set.ofetSet.copyOfsont pratiques pour des ensembles immuables. - Le bon choix dépend surtout de l’ordre attendu, de la mutabilité et du volume de données.
Ce qu’un set garantit vraiment en Java
Le point de départ est simple: un Set ne contient pas de doublons. En Java, l’unicité repose sur equals et hashCode pour la plupart des implémentations, donc deux objets jugés égaux ne pourront pas vivre deux fois dans le même ensemble. En pratique, c’est ce qui rend le Set utile pour nettoyer une liste de valeurs répétées, stocker des identifiants uniques ou vérifier rapidement la présence d’un élément.
Set tags = new HashSet<>();
tags.add("java");
tags.add("api");
tags.add("java"); // ignoré
System.out.println(tags.size()); // 2 Il faut aussi garder en tête que l’ordre n’est pas un contrat général du Set. Certaines implémentations conservent l’ordre d’insertion, d’autres trient, d’autres ne promettent rien du tout. Enfin, le support de null varie: HashSet l’accepte une fois, alors que Set.of le refuse entièrement et TreeSet pose souvent problème avec la comparaison naturelle.
Une fois ces règles comprises, le vrai choix se joue sur la structure concrète à instancier.
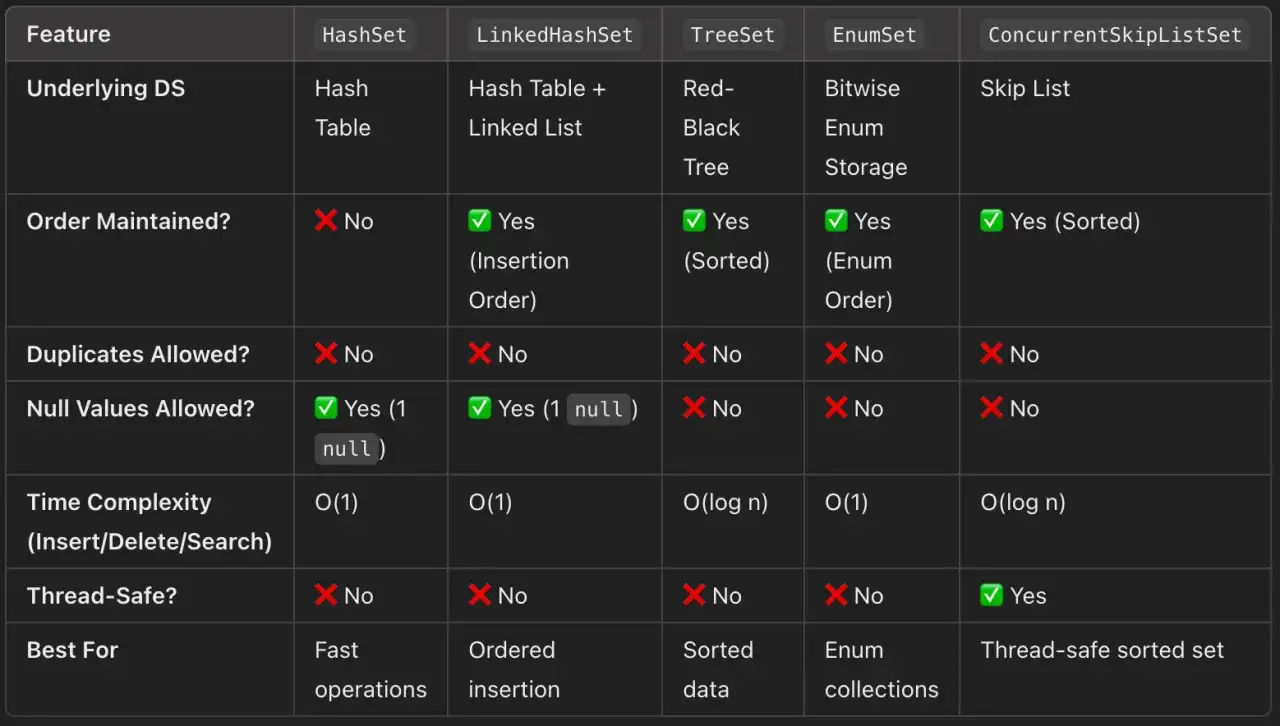
Choisir la bonne implémentation selon le besoin
Quand je crée un nouveau Set, je ne pars jamais d’un réflexe abstrait. Je regarde d’abord trois questions: faut-il garder l’ordre, faut-il trier, et faut-il pouvoir modifier la collection plus tard? La réponse à ces trois points suffit souvent à éliminer 80 % des hésitations.
| Implémentation | Ordre | Mutabilité | null |
Cas d’usage |
|---|---|---|---|---|
HashSet |
Non garanti | Oui | Oui, une seule valeur | Choix par défaut quand seule l’unicité compte |
LinkedHashSet |
Ordre d’insertion | Oui | Oui, une seule valeur | Exports, journaux, réponses API où l’ordre doit rester stable |
TreeSet |
Trié | Oui | Généralement non en tri naturel | Listes ordonnées, navigation alphabétique, filtres classés |
Set.of / Set.copyOf
|
Dépend de l’implémentation interne | Non | Non | Jeux de données figés, constantes, configuration |
EnumSet |
Ordre des constantes enum | Oui | Non | Ensembles d’énumérations, très compact et rapide |
Sur le plan des coûts, il y a une différence nette: HashSet offre en moyenne des accès en O(1), alors que TreeSet monte à O(log n) à cause du tri. Dans un projet réel, ce détail compte surtout quand la collection grossit ou quand les opérations contains et add sont très fréquentes. Si vous connaissez déjà le volume attendu, je conseille aussi de pré-calibrer la capacité initiale: avec le facteur de charge par défaut de 0,75, un ensemble destiné à 10 000 éléments mérite plutôt une capacité proche de 13 334 pour limiter les redimensionnements.
Quand la collection doit rester figée, la logique change complètement: on passe aux fabriques immuables.
Utiliser Set.of et Set.copyOf quand les données ne doivent plus bouger
Pour des valeurs fixes, j’évite de créer un HashSet puis de le verrouiller à la fin. Depuis Java 9, Set.of permet de créer un ensemble immuable directement, avec un code plus lisible et moins de bruit autour de l’intention métier.
Set pays = Set.of("France", "Italie", "Espagne"); Cette approche est excellente pour des constantes, des options permises ou des listes de référence. Elle a aussi des contraintes claires: pas de doublons, pas de null, et aucune modification possible après création. Si l’on tente d’insérer une valeur en trop ou une valeur nulle, on obtient une exception au lieu d’un ensemble « un peu sale » mais silencieux.
Set.copyOf est utile quand la source existe déjà. Contrairement à Collections.unmodifiableSet(...), qui enveloppe une collection existante, Set.copyOf donne une copie non modifiable du contenu au moment de l’appel. C’est souvent le meilleur choix quand je veux normaliser une collection en supprimant les doublons tout en figeant le résultat.
List tags = List.of("java", "api", "java");
Set uniques = Set.copyOf(tags); Si la source doit continuer à évoluer, il faut alors construire un ensemble mutable à partir d’une collection ou d’un flux. C’est là que les choses deviennent vraiment pratiques.
Construire un set à partir d’une collection ou d’un flux
Le cas le plus courant en production, ce n’est pas la création à partir de rien, mais la conversion depuis une liste, un tableau ou un stream. Dans ce contexte, le point clé est simple: si tu veux un ensemble mutable et concret, instancie la bonne implémentation directement au lieu de compter sur une conversion trop générique.
List couleurs = List.of("rouge", "bleu", "rouge");
Set set1 = new HashSet<>(couleurs);
Set set2 = new LinkedHashSet<>(couleurs); Cette forme est propre, rapide à lire et supprime les doublons d’un seul coup. Si tu pars d’un tableau, la logique est la même avec Arrays.asList(...) ou, mieux encore, avec un flux quand tu enchaînes déjà des transformations.
Set uniques = noms.stream()
.filter(nom -> nom.length() > 2)
.collect(Collectors.toCollection(HashSet::new));
Set immuables = noms.stream()
.filter(nom -> nom.length() > 2)
.collect(Collectors.toUnmodifiableSet()); Je fais attention à un détail souvent oublié: Collectors.toSet() ne garantit pas l’implémentation concrète. En d’autres termes, on obtient bien un Set, mais pas forcément un HashSet ni un ordre précis. Si le type concret compte vraiment, je préfère toCollection(HashSet::new) ou toCollection(LinkedHashSet::new).
À ce stade, les erreurs ne sont plus conceptuelles mais presque toujours liées à des hypothèses cachées sur le comportement de la collection.
Les erreurs qui reviennent le plus souvent
Quand un Set se comporte « mal », la cause vient rarement du JDK lui-même. Elle vient plutôt d’une mauvaise hypothèse sur la manière dont les éléments sont comparés ou ordonnés. Voici les erreurs que je vois le plus souvent.
- Penser que
HashSetconserve l’ordre d’insertion. Il ne le promet pas, et cet ordre peut varier selon les versions ou la charge. - Utiliser
Set.ofavec des doublons ounull. L’API est volontairement stricte et renvoie une erreur au lieu de corriger silencieusement l’entrée. - Oublier de redéfinir
hashCodequand on redéfinitequals. Dans unSet, ce déséquilibre casse la déduplication. - Modifier après insertion un objet dont les champs servent à
equalsouhashCode. Le contenu devient alors difficile à retrouver. - Choisir
TreeSetsans comparateur cohérent. Si la comparaison et l’égalité racontent deux histoires différentes, les résultats deviennent surprenants. - Supposer qu’un
Setest thread-safe par défaut. Si plusieurs threads l’écrivent en même temps, il faut une stratégie de concurrence explicite.
Le piège le plus coûteux, à mon sens, reste celui des objets métier. Un Set ne corrige pas des classes mal définies; il les expose. Dès que les éléments sont des entités personnalisées, je vérifie toujours les contrats equals et hashCode avant même de discuter de l’implémentation de la collection.
Avec ces pièges écartés, le bon réflexe devient presque automatique.
Le réflexe que j’applique pour ne pas me tromper
Dans un projet Java classique, mon choix par défaut est très stable: HashSet si seule l’unicité compte, LinkedHashSet si l’ordre doit rester lisible, TreeSet si le tri est une vraie exigence, et Set.of si la donnée doit rester immuable. Si je manipule une énumération, je regarde rapidement EnumSet, parce qu’il est souvent plus efficace et plus clair qu’un ensemble générique.
Quand je connais le volume à l’avance, je pense aussi à la capacité initiale. Ce détail est discret, mais il évite des reallocations inutiles et améliore la stabilité des performances quand le jeu de données grossit. Sur de gros ensembles, ce n’est pas un micro-optimisation décorative: c’est souvent la différence entre un code correct et un code qui reste fluide en charge.
En pratique, créer un nouveau set en Java revient donc moins à mémoriser une syntaxe qu’à choisir la bonne sémantique: mutable ou non, ordonné ou non, trié ou non. Une fois cette grille de lecture en place, le code devient plus lisible, plus prévisible et beaucoup plus simple à faire évoluer.