
Un identifiant UUID permet de générer des clés uniques sans dépendre d’une base centralisée, ce qui reste pratique dès qu’une application Java doit dialoguer avec plusieurs services, files de messages ou bases de données. Je vais aller droit au but: comment le créer, comment le lire, quand choisir une version aléatoire ou temporelle, et quels pièges évitent les mauvaises surprises en production. Le point important n’est pas seulement de produire une valeur unique, mais de choisir un format qui reste exploitable par la suite.
Les points à retenir avant d’implémenter des UUID en Java
- `UUID.randomUUID()` génère un UUID v4 opaque, simple et difficile à prédire.
- `UUID.ofEpochMillis(...)` apporte un UUIDv7 natif dans Java 26+ pour mieux ordonner les données dans le temps.
- `UUID.nameUUIDFromBytes(...)` est déterministe: même entrée, même sortie.
- `UUID.fromString(...)` valide la forme canonique et lève une exception si la chaîne est invalide.
- Un UUID n’est pas un secret: il sert à identifier, pas à authentifier.
Ce qu’un UUID change vraiment dans une application Java
Un UUID est une valeur de 128 bits, le plus souvent affichée sous la forme `8-4-4-4-12`, soit 36 caractères avec les tirets. En Java, la classe `java.util.UUID` est immuable, comparable et sérialisable: je peux donc la stocker dans une collection, la passer d’un service à l’autre, puis la relire sans perte de sens.
Le vrai intérêt apparaît quand je veux éviter un compteur centralisé. Une base auto-incrémentée fonctionne très bien dans un monolithe, mais elle devient plus fragile dès qu’on répartit la génération d’IDs entre plusieurs services, environnements ou régions. Un UUID réduit cette dépendance à presque rien, ce qui simplifie les architectures distribuées.
Je garde toutefois un réflexe simple: unique ne veut pas dire optimal pour tous les usages. Un UUID aléatoire n’est pas idéal pour l’ordonnancement en base, et un UUID temporel peut révéler l’heure de création. C’est ce compromis qu’il faut clarifier avant d’écrire la première ligne de code.
Une fois ce cadre posé, la vraie question devient: quelle méthode de génération correspond à ton besoin réel?
Générer, parser et valider un UUID sans sortir du standard
La classe standard couvre plusieurs scénarios, et je préfère les séparer nettement plutôt que de tout mélanger sous le mot "UUID".
| Méthode | Version | Ce que ça fait | Quand je l’utilise |
|---|---|---|---|
UUID.randomUUID() |
v4 | Génère un identifiant pseudo-aléatoire avec un générateur cryptographiquement fort | Identifiant opaque par défaut |
UUID.nameUUIDFromBytes(...) |
v3 | Dérive un UUID déterministe à partir d’un tableau d’octets | Identifiant stable fondé sur un nom métier |
UUID.fromString(...) |
n/a | Parse la représentation canonique | Validation d’entrée ou désérialisation |
UUID.ofEpochMillis(...) |
v7 | Construit un UUID temporel à partir d’un timestamp Unix en millisecondes | Tri temporel et meilleure localité d’index |
UUID id = UUID.randomUUID();Je l’utilise quand je veux un identifiant opaque, simple à générer et difficile à prédire. C’est le choix le plus sûr par défaut quand je n’ai pas de contrainte d’ordre ni de reproductibilité.
UUID stable = UUID.nameUUIDFromBytes(
"billing:invoice:42".getBytes(StandardCharsets.UTF_8)
);Ici, la sortie dépend uniquement de l’entrée. C’est utile quand je veux dériver un identifiant stable à partir d’une clé métier, mais ce n’est pas un substitut à une valeur aléatoire. Je fige aussi l’encodage en UTF-8, sinon je m’expose à des différences entre environnements.
try {
UUID id = UUID.fromString(input);
} catch (IllegalArgumentException ex) {
// format invalide
}Pour un flux entrant, cette méthode fait le travail de validation sans bricolage regex. Elle accepte la forme canonique avec tirets, et la casse ne pose pas de problème; en revanche, un format incomplet ou mal structuré échoue vite.
UUID eventId = UUID.ofEpochMillis(System.currentTimeMillis());Avec Java 26 et plus, c’est la porte d’entrée native vers le UUIDv7. Le bénéfice principal est l’alignement temporel, mais la monotonie dépend toujours de la qualité de l’horodatage que tu fournis. L’API refuse d’ailleurs les valeurs hors plage, ce qui évite les entrées absurdes.
Le choix n’est pourtant pas seulement une affaire d’API; la version influence aussi l’ordre, les index et la lisibilité opérationnelle.
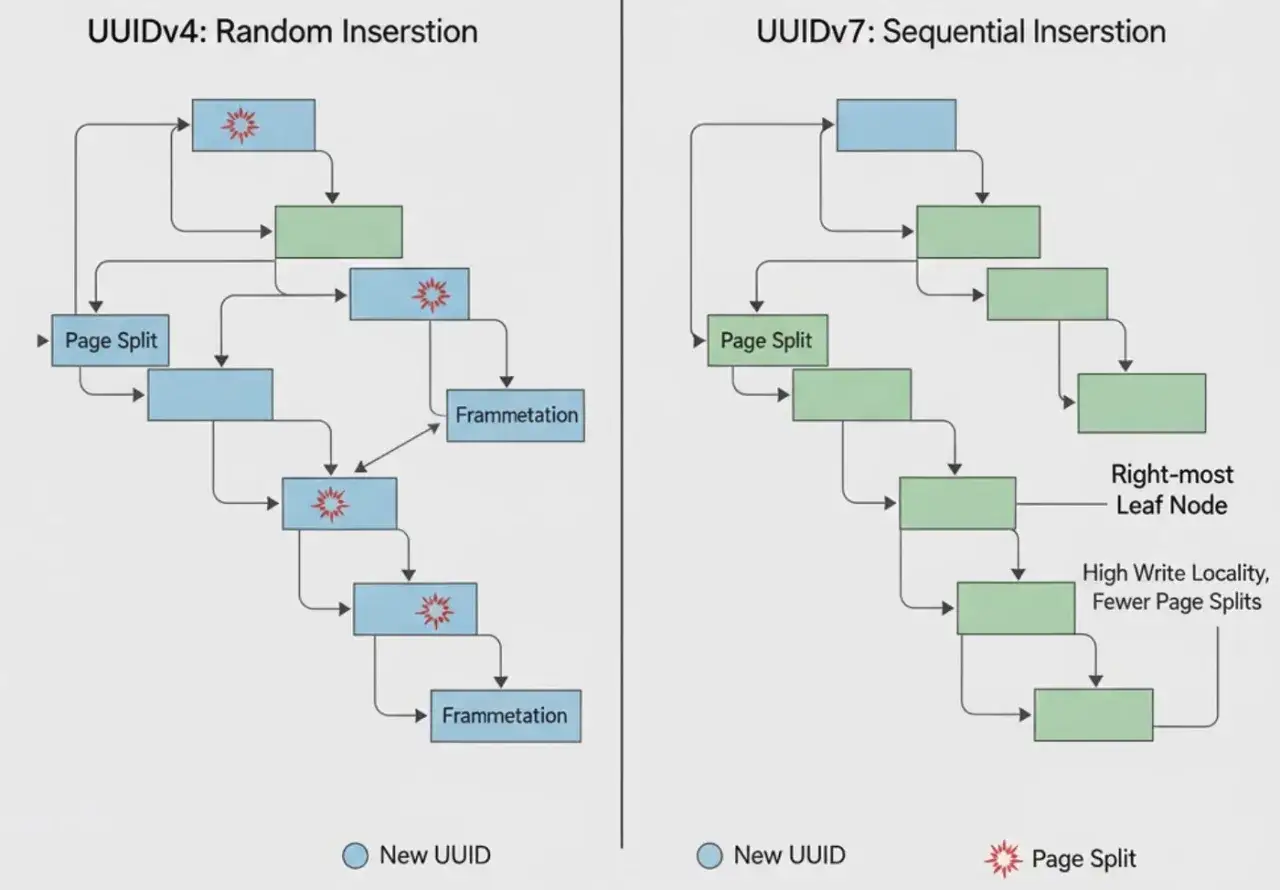
Choisir entre v4, v7 et un identifiant déterministe
En 2026, le point vraiment intéressant n’est plus seulement l’opposition entre aléatoire et déterministe. Le cadre moderne, aligné sur RFC 9562, donne à la version 7 une place très concrète dès qu’on veut garder un tri temporel propre sans repasser par un identifiant centralisé.
| Version | Atout principal | Limite principale | Mon usage typique |
|---|---|---|---|
| v4 | Opaque, simple, universel | Pas d’ordre temporel utile, index plus dispersé | IDs publics, corrélation, objets métier sans contrainte de tri |
| v7 | Meilleure localité en écriture et lecture temporelle | Expose une partie de la chronologie, disponible nativement à partir de Java 26 | Événements, journaux, tables volumineuses, inserts fréquents |
| v3 | Reproductible à partir d’un nom ou d’une clé stable | Déterministe, donc pas adapté à un usage secret ou aléatoire | Correspondance stable entre une donnée métier et un identifiant |
Si l’ID transite dans une URL visible par un client et que je veux qu’il reste difficile à interpréter, je reste souvent sur v4. Si l’ID sert surtout à écrire vite en base et à conserver un ordre temporel exploitable, v7 devient bien plus intéressant. Et si je dois produire la même valeur à partir d’une même entrée, v3 garde sa place, à condition d’assumer son côté entièrement déterministe.
Je laisse de côté la version 1 pour la plupart des projets neufs: on la croise surtout dans l’héritage ou l’interopérabilité, pas comme premier choix d’architecture.
À ce stade, le bon format est plus important que le simple fait d’avoir "un UUID". Reste à voir comment l’intégrer proprement dans une API et dans une base de données.
Intégrer un UUID proprement dans une base de données et une API
En API REST, je renvoie presque toujours l’UUID sous sa forme texte canonique. C’est lisible, compatible avec les clients et simple à journaliser. Côté Java, je garde le type `UUID` le plus longtemps possible, puis je le sérialise au bord du système plutôt que de le convertir trop tôt en `String`.
@Entity
class EventEntity {
@Id
private UUID id;
}Dans les frameworks Java modernes, `UUID` est un type naturel pour une clé primaire ou un identifiant métier. Je l’utilise aussi comme correlation ID dans les logs distribués: ce n’est pas un gadget, c’est souvent ce qui permet de suivre une requête de bout en bout quand plusieurs services se répondent.
| Représentation | Taille | Avantage | Inconvénient |
|---|---|---|---|
CHAR(36) |
36 caractères | Simple, lisible, portable | Plus volumineux dans l’index et les échanges |
BINARY(16) |
16 octets | Compact, plus léger pour les index | Moins lisible, conversion nécessaire |
Si je contrôle le schéma, je préfère souvent le binaire pour limiter la taille des index. Si je privilégie la simplicité ou la portabilité, le texte reste un choix parfaitement acceptable. Ce qui compte, ce n’est pas d’être "puriste", mais de ne pas pénaliser inutilement la table la plus sollicitée du système.
C’est aussi là que les erreurs de conception apparaissent le plus vite, surtout quand on confond facilité d’affichage et bon design d’ID.
Les erreurs que je vois le plus souvent avec les UUID
- Confondre UUID et secret. Un UUID n’est pas un mécanisme d’authentification. Il identifie, il ne protège pas.
- Tout convertir en chaîne trop tôt. Je garde le type `UUID` dans le cœur du code et je ne passe en texte qu’à la frontière.
- Choisir v4 comme clé primaire sans réfléchir à l’index. Ça fonctionne, mais l’écriture peut devenir moins agréable à grande échelle.
- Prendre `nameUUIDFromBytes()` pour une valeur aléatoire. La méthode est déterministe, donc parfaitement prévisible à entrée égale.
- Oublier de gérer `IllegalArgumentException` à l’entrée. Si tu désérialises des données externes, il faut traiter les UUID invalides proprement.
- Négliger l’horodatage source pour v7. Si tu veux un ordre strictement cohérent, le timestamp fourni doit lui-même être monotone.
Ces pièges reviennent parce que l’UUID donne une impression de simplicité totale. En réalité, il faut le traiter comme un vrai type métier, pas comme une chaîne magique qu’on jette partout.
Mon réflexe final est donc de choisir selon la propriété dominante, pas selon le prestige du format.
Ce que je garderais en tête avant de choisir un identifiant en production
Si le besoin est simple et que je veux un identifiant opaque, je prends `UUID.randomUUID()` sans hésiter. Si le besoin principal est l’ordre d’écriture et une meilleure localité d’index, je passe à `UUID.ofEpochMillis(...)` dès que le socle est en Java 26, ou j’accepte une librairie tierce sur une version plus ancienne. Et si je dois dériver un identifiant stable à partir d’une entrée connue, `UUID.nameUUIDFromBytes(...)` reste pertinent, à condition de figer l’encodage et d’assumer son caractère déterministe.
Au fond, le bon choix n’est pas celui qui semble le plus moderne, mais celui qui sert le mieux la donnée, le stockage et l’exploitation. C’est cette discipline-là qui évite les architectures élégantes en apparence et pénibles à maintenir ensuite.