
Les trois décisions qui comptent avant d’implémenter Fibonacci
- Fixer la convention dès le départ, le plus souvent avec F0 = 0 et F1 = 1.
- Choisir le bon retour : un terme unique, une liste ou un générateur.
- Éviter la récursion naïve dès que n commence à monter, car elle devient vite coûteuse.
- Prévoir la validation des entrées, surtout pour les valeurs négatives.
- Préférer la boucle pour un usage courant, et le cache seulement si les appels se répètent.
Ce qu’il faut décider avant d’écrire le code
Le point le plus mal compris, c’est rarement l’algorithme. C’est la définition exacte de ce que la fonction doit renvoyer. Je vois encore souvent des confusions entre le n-ième terme et les n premiers termes, ou entre les conventions F0 = 0, F1 = 1 et F1 = 1, F2 = 1. Si cette base n’est pas claire, le code peut être “correct” mais produire un résultat inattendu.
Le point de départ
Dans un contexte Python classique, je pars presque toujours sur F0 = 0 et F1 = 1. C’est lisible, standard, et cela facilite les tests. Si vous devez travailler avec une convention différente, le bon réflexe est de la documenter dans la docstring, pas de la cacher dans les lignes de calcul.
Lire aussi : π en Python - Le guide complet pour des calculs précis
Le type de sortie
Une fonction peut renvoyer un entier, une liste ou un itérateur. Ce choix change tout. Si vous voulez juste le terme Fn, une fonction simple suffit. Si vous voulez parcourir la suite, un générateur est plus propre. Si vous voulez réutiliser les mêmes résultats plusieurs fois, le cache devient intéressant. Cette distinction me sert ensuite à choisir la bonne implémentation, sans sur-ingénierie.
Une fois ce cadre posé, la version la plus sûre à écrire est presque toujours la plus simple : une boucle.
La version avec boucle que j’utilise par défaut
Pour calculer un terme précis, la solution itérative est celle que je recommande en premier. Elle est courte, facile à lire, et sa complexité reste linéaire. En pratique, cela veut dire qu’elle scale proprement tant que n reste raisonnable, sans explosion du nombre d’appels comme avec la récursion naïve.
def fibonacci(n: int) -> int:
if n < 0:
raise ValueError("n doit être positif ou nul")
if n < 2:
return n
a, b = 0, 1
for _ in range(2, n + 1):
a, b = b, a + b
return bCette version a trois avantages concrets. D’abord, elle est prévisible : un seul passage dans la boucle. Ensuite, elle consomme très peu de mémoire, car elle garde seulement les deux derniers termes. Enfin, elle se teste facilement avec quelques cas simples : 0, 1, 2, 10 et une valeur négative.
Si l’on veut les premiers termes de la suite plutôt qu’un seul nombre, il suffit d’adapter la logique et de produire une collection. Pour une suite destinée à être consommée en aval, j’évite de construire une liste géante si un générateur suffit. La récursion, elle, raconte une histoire plus élégante sur le papier, mais elle a un coût bien réel.
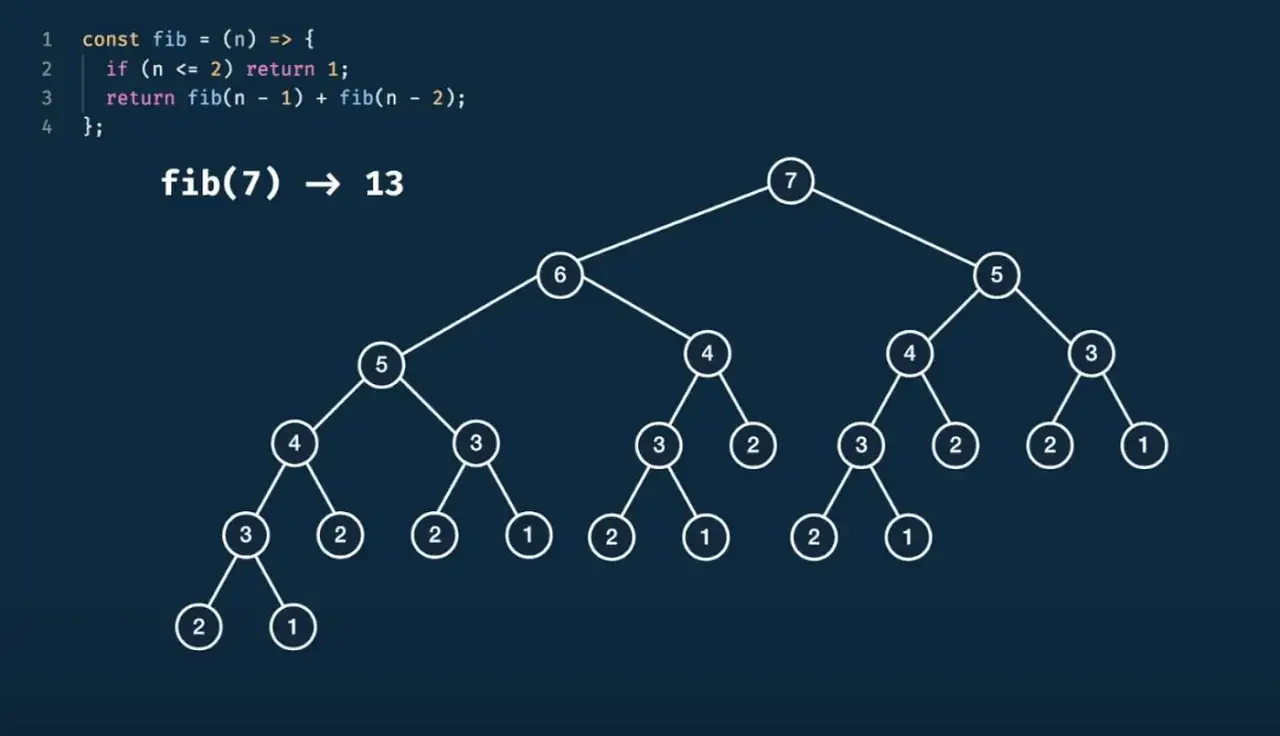
Pourquoi la récursion séduit, mais piège vite
La version récursive est souvent celle que l’on écrit en premier quand on découvre Fibonacci. Elle reflète bien la définition mathématique : chaque terme est la somme des deux précédents. Le problème, c’est qu’en Python cette beauté conceptuelle cache une redondance massive des calculs.
def fibonacci_recursive(n: int) -> int:
if n < 0:
raise ValueError("n doit être positif ou nul")
if n < 2:
return n
return fibonacci_recursive(n - 1) + fibonacci_recursive(n - 2)Le défaut principal est simple : la fonction recalcule plusieurs fois les mêmes valeurs. Pour F10, cela reste supportable. Pour F30 ou F40, le nombre d’appels grimpe très vite. On bascule alors vers une complexité exponentielle, ce qui rend l’approche inadaptée à un usage sérieux.
Il y a aussi une contrainte moins visible : la pile d’appels. Python n’est pas conçu pour encaisser de longues chaînes de récursion sans limite. La version récursive reste donc excellente pour expliquer le principe, mais je la considère comme une version pédagogique, pas comme un choix de production.
Si l’on veut garder l’écriture récursive tout en supprimant le vrai problème, il faut ajouter une couche de cache. C’est là que la mémoïsation devient utile.
Quand la mémoïsation change vraiment la donne
La documentation officielle Python présente cache comme un cache léger et non borné, équivalent à lru_cache(maxsize=None). C’est exactement le genre d’outil qui transforme une récursion coûteuse en solution propre, parce qu’il évite de recalculer les mêmes termes encore et encore.
from functools import cache
@cache
def fibonacci_cached(n: int) -> int:
if n < 0:
raise ValueError("n doit être positif ou nul")
if n < 2:
return n
return fibonacci_cached(n - 1) + fibonacci_cached(n - 2)Avec ce décorateur, chaque valeur est calculée une fois, puis réutilisée. On garde la lisibilité de la récursion, mais on supprime l’essentiel du surcoût. En retour, on accepte une mémoire supplémentaire pour stocker les résultats. Ce compromis est souvent raisonnable quand on appelle plusieurs fois la fonction avec des entrées proches.
Je n’utilise pas ce pattern par réflexe dans tous les projets. Il est pertinent si plusieurs appels répètent les mêmes valeurs, si l’on veut garder une structure récursive pour des raisons pédagogiques, ou si l’on doit comparer rapidement différentes entrées. Sinon, la boucle reste plus sobre. Il reste alors à choisir entre une sortie matérialisée en mémoire et une sortie produite à la demande.
Choisir entre boucle, cache et générateur
Une fois les variantes en main, la vraie question devient : quel outil sert le mieux le besoin réel ? Pour un calcul isolé, je privilégie la boucle. Pour un accès répété avec les mêmes arguments, la mémoïsation a du sens. Pour produire une suite terme par terme sans tout stocker, le générateur est plus élégant.
| Méthode | Temps | Mémoire | Je la choisis quand |
|---|---|---|---|
| Boucle | O(n) | O(1) | Je veux le terme n-ième de manière simple et robuste. |
| Récursion naïve | Exponential, ≈ O(φ^n) | O(n) | Je démontre l’idée, mais pas pour un usage réel. |
| Récursion avec cache | O(n) | O(n) | Les mêmes entrées reviennent souvent et je veux garder une écriture récursive. |
| Générateur | O(n) pour n termes | O(1) | Je veux parcourir la suite sans la stocker entièrement. |
Le générateur mérite une place à part, parce qu’il correspond très bien à la philosophie de Python. La documentation Python rappelle qu’une fonction qui utilise yield devient un générateur : elle produit les valeurs une par une, au lieu de construire un objet complet dès le départ.
def fibonacci_sequence(count: int):
if count < 0:
raise ValueError("count doit être positif ou nul")
a, b = 0, 1
for _ in range(count):
yield a
a, b = b, a + bCette version est très pratique pour afficher les n premiers termes, alimenter une boucle, ou traiter la suite dans un pipeline. Elle évite le gaspillage mémoire, mais elle ne remplace pas toujours une liste. Si vous devez indexer plusieurs fois les valeurs obtenues, une liste reste parfois plus confortable. Le bon choix dépend donc moins de Fibonacci lui-même que de l’usage que vous faites des résultats.
Avant d’arrêter une implémentation, j’examine toujours les erreurs de logique les plus courantes, parce que ce sont elles qui rendent une fonction “presque bonne” mais fausse.
Les erreurs qui cassent le plus souvent une fonction Fibonacci
- Confondre le rang et la valeur : F10 n’est pas la dixième valeur affichée selon toutes les conventions possibles, c’est le terme à l’indice 10 dans une convention précise.
- Oublier le cas n = 0 ou n = 1, ce qui crée des résultats incohérents dès les premières entrées.
- Retourner un print au lieu de retourner la valeur, ce qui rend la fonction difficile à réutiliser.
- Mélanger génération de suite et calcul d’un terme, alors que ces deux besoins méritent souvent deux fonctions distinctes.
- Ignorer les entrées négatives, qui devraient lever une exception explicite plutôt que produire un résultat absurde.
- Sous-estimer la taille des nombres : en Python, les entiers sont arbitrairement grands, mais le coût d’addition augmente quand les valeurs grossissent.
Le dernier point est important. Il ne s’agit pas d’un “bug” de Python, mais d’un effet réel sur les performances. Plus les termes deviennent grands, plus l’addition de grands entiers prend du temps. Pour des valeurs modestes, on ne le sent pas. Pour des suites longues, cela compte.
Quand je révise ce type de fonction, je fais aussi attention aux noms. Une fonction nommée fibonacci devrait faire une seule chose clairement définie. Si elle imprime, retourne une liste, accepte des cas exotiques et calcule des indices dans le même bloc, elle devient vite moins fiable qu’elle n’en a l’air. C’est précisément pour cela que je préfère une version finale courte, documentée et testable.
Ce que je livrerais pour un vrai projet Python
Pour un code propre en 2026, je choisirais une version itérative pour le calcul d’un terme, et une fonction séparée si j’ai besoin de parcourir la suite. J’ajouterais une docstring courte, une validation d’entrée et quelques tests unitaires. Ce trio suffit souvent à éviter 80 % des erreurs qui apparaissent plus tard en revue de code.
def fibonacci(n: int) -> int:
"""Retourne le terme F_n avec F_0 = 0 et F_1 = 1."""
if n < 0:
raise ValueError("n doit être positif ou nul")
if n < 2:
return n
a, b = 0, 1
for _ in range(2, n + 1):
a, b = b, a + b
return b- Je documente la convention dès la docstring, pour éviter les ambiguïtés sur le point de départ.
- Je teste les bornes avec 0, 1 et 2, parce que c’est là que les erreurs apparaissent le plus vite.
- Je garde la récursion pour l’explication, pas pour le chemin nominal d’exécution.
-
J’utilise
cacheuniquement si plusieurs appels répètent les mêmes calculs ou si je veux comparer l’approche à la boucle. - Je choisis un générateur si le besoin réel est de parcourir une suite, pas de la stocker.
En pratique, la meilleure réponse à la suite de Fibonacci en Python est rarement la plus sophistiquée. Pour un calcul isolé, la boucle gagne presque toujours. Pour une suite consommée en streaming, le générateur est plus élégant. Et pour un exercice pédagogique, la récursion mérite sa place tant qu’on garde à l’esprit ses limites réelles.