 - Maîtrisez la casse et évitez les pièges")
Mettre une chaîne en minuscules paraît simple, mais cette opération joue un rôle important dans le nettoyage de données, les comparaisons insensibles à la casse et le tri de textes. Ici, je détaille ce que fait réellement la méthode `str.lower()`, comment l’utiliser proprement, quand lui préférer une alternative plus robuste, et quels pièges éviter dans un projet Python concret.
Les points à retenir sur `str.lower()` en Python
- `str.lower()` renvoie une nouvelle chaîne et ne modifie jamais l’originale.
- Elle convertit les caractères sensibles à la casse en minuscules, selon les règles Unicode.
- Elle ne supprime ni les accents, ni les espaces, ni la ponctuation.
- Pour des comparaisons internationales plus fiables, `casefold()` est souvent plus adaptée.
- En pratique, je l’utilise surtout pour normaliser des saisies, préparer un tri ou simplifier une comparaison.
Ce que fait réellement `str.lower()`
La méthode `lower()` prend une chaîne et renvoie sa version en minuscules. Comme le rappelle la documentation Python, elle s’appuie sur les règles Unicode, ce qui veut dire qu’elle ne se limite pas à l’alphabet ASCII. Concrètement, les lettres comme A, B ou É sont converties, mais les chiffres, les espaces et la ponctuation restent inchangés.
Le point que je vois souvent oublié, c’est la non-mutabilité des chaînes en Python. Une chaîne ne change pas sur place. Si tu appelles `lower()`, tu obtiens un nouvel objet, et la chaîne d’origine reste intacte.
| Entrée | Résultat | Ce qu’il faut comprendre |
|---|---|---|
"Bonjour" |
"bonjour" |
Conversion classique des lettres |
"ÉCOLE" |
"école" |
Les caractères accentués sont aussi traités |
"Python 3.14" |
"python 3.14" |
Les chiffres restent inchangés |
"A-B" |
"a-b" |
La ponctuation ne bouge pas |
"ß" |
"ß" |
Le caractère est déjà en minuscule, donc il ne change pas |
Cette logique simple suffit dans beaucoup de cas, mais il faut la relier à un usage précis. C’est justement là que la syntaxe et les exemples deviennent utiles.
La syntaxe et quelques exemples simples
La forme la plus courante est directe : chaine.lower(). J’aime cette approche parce qu’elle reste lisible même dans du code qui traite plusieurs transformations de texte à la suite.
message = "Bonjour, Paris"
normalise = message.lower()
print(normalise) # bonjour, paris
print(message) # Bonjour, ParisDans un flux réel, je l’utilise souvent avec d’autres opérations. Par exemple, pour une saisie utilisateur, j’enchaîne fréquemment strip() puis lower() afin de retirer les espaces parasites avant de comparer :
reponse = input("Répondre oui/non : ").strip().lower()
if reponse == "oui":
print("Validation acceptée")Ce petit enchaînement évite un bon paquet d’erreurs absurdes, comme une réponse écrite en majuscules ou entourée d’espaces. La prochaine question logique, c’est donc : dans quels cas cette normalisation est-elle vraiment utile dans un projet ?
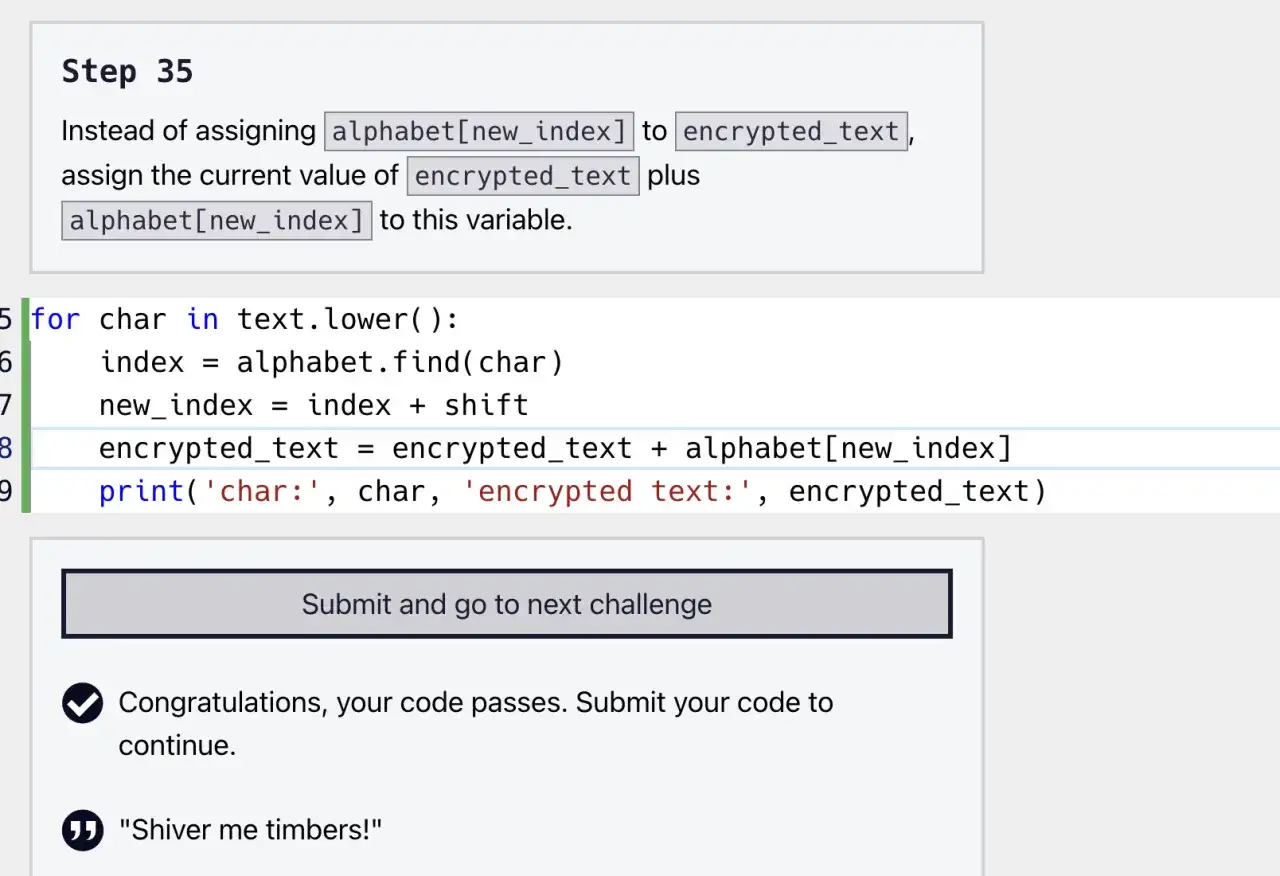
Quand je l’utilise pour nettoyer des données
La vraie valeur de `lower()` apparaît quand tu traites des données venues de l’extérieur : formulaire web, CSV, API, export d’outil interne ou logs. Dans ce contexte, la casse devient souvent un bruit inutile. Si tu compares Admin, ADMIN et admin, tu veux souvent les considérer comme équivalents.
| Cas d’usage | Pourquoi `lower()` aide | Point de vigilance |
|---|---|---|
| Champs de formulaire | Uniformise les réponses avant comparaison | Garder la valeur d’origine si elle doit être affichée plus tard |
| Tags et catégories | Évite les doublons dus à la casse | Ne pas écraser la donnée brute si elle sert au reporting |
| Imports CSV | Simplifie la détection de valeurs identiques | Vérifier les types avant d’appeler la méthode |
| Tri de listes de chaînes | Produit un tri plus cohérent visuellement | Utiliser une clé de tri, pas une transformation définitive si ce n’est pas nécessaire |
Pour trier, je préfère en général passer une clé plutôt que transformer toute la liste à l’avance :
noms = ["zoé", "Alice", "bernard", "Émile"]
trie = sorted(noms, key=str.lower)La documentation Python recommande d’ailleurs ce type d’approche avec une fonction de clé, parce que la transformation est calculée une seule fois par élément. C’est simple, lisible, et souvent plus propre que de bricoler un tri maison. Une fois ce réflexe posé, la vraie question devient celle de la robustesse linguistique : `lower()` suffit-il toujours ?
Pourquoi `casefold()` est parfois meilleur
Pour une comparaison insensible à la casse, `lower()` est souvent suffisant. Mais dès qu’on travaille avec du texte international, je me méfie d’un usage trop naïf. La documentation Python présente `casefold()` comme une version plus agressive de la mise en minuscules, pensée pour faire disparaître les distinctions de casse dans les comparaisons.
Le cas classique est l’allemand `ß` : avec `lower()`, le caractère ne change pas puisqu’il est déjà minuscule ; avec `casefold()`, il devient ss. C’est précisément ce genre de détail qui fait la différence entre un code “qui marche en apparence” et un code fiable sur des corpus multilingues.
| Méthode | Comportement | Quand je la choisis |
|---|---|---|
lower() |
Convertit les lettres en minuscules selon Unicode | Normalisation simple, nettoyage courant, affichage cohérent |
casefold() |
Réduit plus agressivement les distinctions de casse | Comparaisons robustes sur texte international |
En pratique, je fais souvent ce choix simple : si je veux juste uniformiser une chaîne pour un usage interne, `lower()` suffit ; si je veux comparer des textes venant de plusieurs langues ou fiabiliser une logique de recherche, je passe à `casefold()`. Cette distinction évite pas mal de bugs subtils, mais elle ne règle pas tout, et c’est là que les erreurs classiques apparaissent.
Les erreurs que je vois le plus souvent
Le premier piège, c’est d’oublier que la chaîne originale ne change pas. J’ai déjà vu du code écrit comme si `lower()` modifiait l’objet sur place, alors qu’en réalité il faut récupérer la valeur retournée.
texte = "Python"
texte.lower()
print(texte) # Python, pas pythonLe deuxième piège, c’est d’appeler la méthode sur une valeur qui n’est pas une chaîne. Si une variable peut contenir None, un nombre ou un objet quelconque, il faut d’abord sécuriser le type :
if isinstance(valeur, str) and valeur.lower() == "oui":
print("OK")Le troisième piège, plus discret, consiste à croire que `lower()` nettoie tout. Elle ne supprime ni les accents, ni les espaces, ni les caractères invisibles. Si tu veux enlever des espaces de début et de fin, il faut ajouter `strip()`. Si tu veux gérer des formes Unicode différentes, il faut regarder du côté de la normalisation. Et si tu veux comparer des chaînes sans te faire piéger par la casse, `casefold()` est souvent plus solide.
Enfin, je déconseille d’utiliser `lower()` comme règle universelle de comparaison. Sur un petit projet interne, elle peut suffire. Sur un produit exposé à plusieurs langues ou à des données hétérogènes, je préfère poser une stratégie explicite plutôt que compter sur une transformation implicite. C’est ce réflexe qui évite les surprises au moment où le code sort du cadre de test.
Le réflexe que je recommande avant tout tri ou toute comparaison
Quand je traite du texte dans un projet Python, je pars généralement de cette logique simple : garder la donnée brute, créer une version normalisée pour la logique métier, puis choisir la bonne méthode selon le contexte. En clair, je n’écrase pas l’original si je peux l’éviter.
- Je nettoie souvent avec
strip()puislower()pour des saisies simples. - Je passe à
casefold()quand le texte peut venir de plusieurs langues. - Je compare toujours les deux côtés sur la même forme normalisée.
- Je garde la version d’origine pour l’affichage, les exports ou l’audit.
- Je trie avec
key=str.lowerquand je veux une lecture plus cohérente d’une liste de chaînes.
Au fond, `str.lower()` n’est pas juste une petite méthode pratique. C’est un outil de normalisation simple, fiable et très utile, à condition de savoir où s’arrête sa portée. Si tu gardes en tête la différence entre mise en minuscules, comparaison insensible à la casse et normalisation Unicode, tu écris déjà un code plus propre et plus robuste.