
Les problèmes NP-difficiles occupent une place particulière en informatique théorique, mais leur impact est très concret dès qu’on code un moteur de planification, un algorithme d’optimisation ou un outil qui doit choisir la meilleure combinaison parmi des milliers d’options. Ce texte explique ce qu’est un problème NP difficile, pourquoi il change la façon de programmer, et comment décider si l’on doit chercher l’optimum, une approximation ou une heuristique. J’y détaille aussi les erreurs de raisonnement les plus fréquentes, parce que c’est souvent là que les projets perdent du temps ou promettent plus qu’ils ne peuvent tenir.
Les repères essentiels pour ne pas confondre difficulté théorique et impasse pratique
- Un problème NP-difficile n’est pas forcément impossible à résoudre, mais il devient vite coûteux quand la taille d’entrée augmente.
- La notion repose sur les réductions polynomiales, qui permettent de comparer la difficulté entre problèmes.
- NP, NP-complet et NP-difficile ne désignent pas la même chose, et cette nuance compte en programmation.
- En pratique, on choisit souvent entre solution exacte, approximation, heuristique, paramétrisation ou solveur spécialisé.
- Le bon choix dépend moins de la théorie que de la taille des données, du niveau d’optimalité attendu et du temps de réponse acceptable.
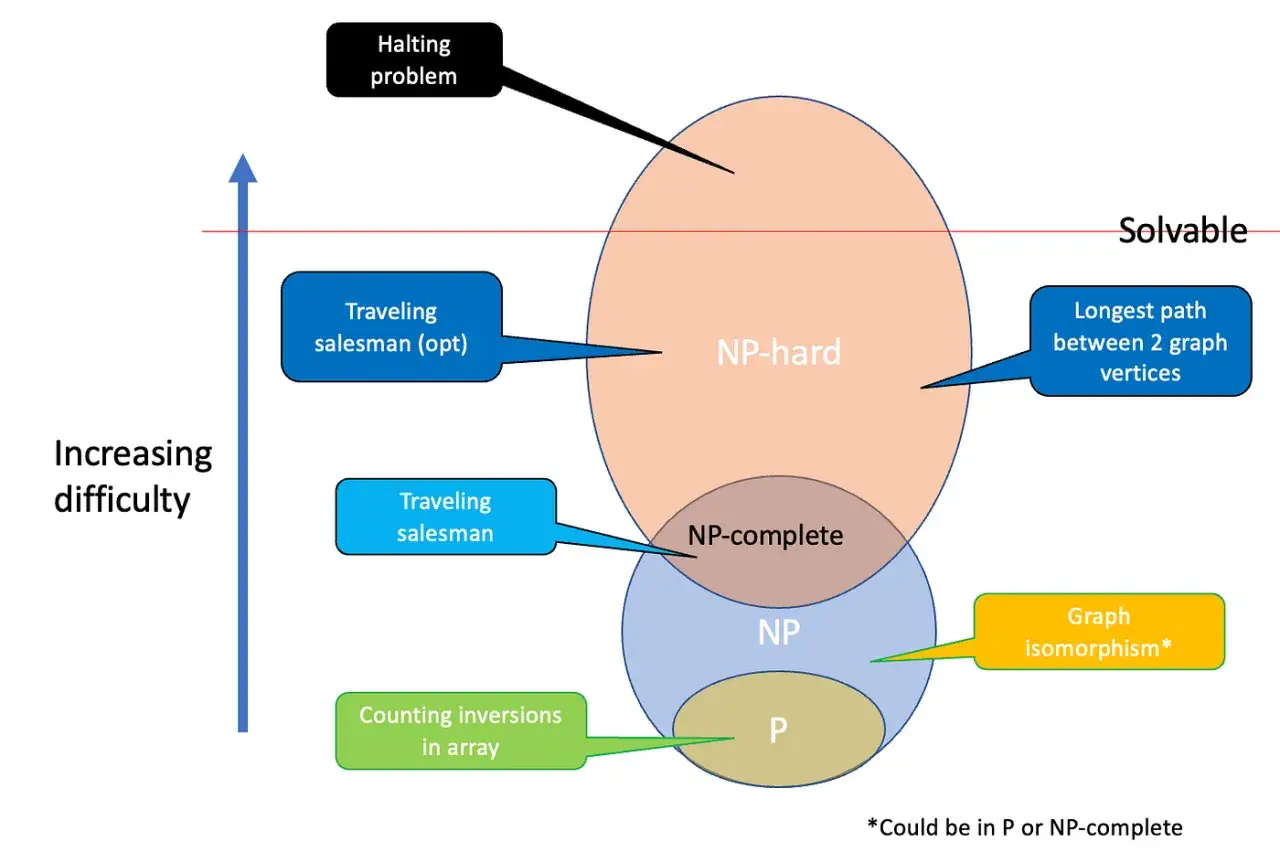
Ce que signifie vraiment être NP-difficile
Je commence toujours par une précision utile : NP-difficile ne veut pas dire la même chose que NP-complet. Un problème est NP-difficile s’il est au moins aussi dur que tous les problèmes de NP, tandis qu’un problème NP-complet est à la fois dans NP et NP-difficile. Autrement dit, un problème NP-complet appartient à la zone la plus célèbre de la complexité, mais un problème NP-difficile peut même sortir de NP si ses solutions ne sont pas vérifiables rapidement.
La manière standard de comparer ces problèmes passe par la réduction polynomiale : on transforme une instance d’un problème A en une instance d’un problème B, en un temps raisonnable, sans faire exploser le calcul. Si A se réduit à B, alors résoudre B permet de résoudre A. C’est cette logique qui explique pourquoi une seule avancée sur un problème central peut avoir des effets en cascade sur toute une famille de problèmes.
| Classe | Idée simple | Ce que cela implique | Exemple typique |
|---|---|---|---|
| P | Résoluble rapidement, au moins en théorie | L’algorithme croît de façon raisonnable avec la taille d’entrée | Tri, plus court chemin dans certains cas |
| NP | Une solution candidate se vérifie vite | On peut contrôler une réponse plus facilement que la trouver | SAT, clique, partition selon la formulation |
| NP-complet | Dans NP et aussi le plus dur de NP | Si l’un d’eux devient facile en temps polynomial, alors tout NP le devient | 3-SAT, voyageur de commerce en version décision |
| NP-difficile | Au moins aussi dur que les problèmes de NP | Peut être hors NP, notamment en optimisation | Version optimisation du TSP, certains problèmes de scheduling |
Dans la pratique, cette distinction évite beaucoup de confusion. Je vois souvent des équipes employer “NP-difficile” comme synonyme de “impossible”, alors que la bonne lecture est plutôt : le pire cas devient explosif, donc il faut changer de stratégie. C’est justement ce changement de stratégie qui compte quand on passe de la théorie à un vrai projet logiciel.
Pourquoi la complexité explose dès qu’on cherche l’optimum
La difficulté vient rarement d’un calcul isolé. Elle vient du nombre de combinaisons possibles. Dès qu’un algorithme doit choisir, parmi des centaines ou des milliers d’options, la recherche exhaustive devient vite inutilisable. Avec 30 éléments, on atteint déjà environ un milliard de combinaisons dans certains schémas binaires ; avec 40, on dépasse facilement le trillion. Ce n’est pas un détail : c’est le moment où la machine cesse d’être un accélérateur et devient un goulot d’étranglement.
Les cas classiques sont parlants. Le sac à dos cherche la meilleure sélection d’objets sous contrainte de capacité. Le problème du voyageur de commerce demande de trouver le meilleur tour entre plusieurs villes. Le coloriage de graphe impose de colorer des nœuds sans conflit. La planification de tâches, l’ordonnancement de production, certaines contraintes de cybersécurité ou de routage peuvent entrer dans la même logique. Le point commun est simple : une petite entrée peut être traitée, mais le nombre de scénarios croît trop vite quand les contraintes se multiplient.
J’insiste sur un point souvent mal compris : vérifier une solution peut être rapide même si la trouver est très difficile. Cette différence explique pourquoi NP est si important. On peut parfois contrôler en quelques millisecondes qu’une affectation, un planning ou une tournée respecte toutes les règles, sans pour autant disposer d’un moyen efficace pour générer la meilleure solution possible.
Comment repérer ce type de problème dans un projet
Dans un vrai projet, le premier indice n’est pas le mot “NP-difficile”, mais le comportement du problème quand on ajoute des contraintes. Si l’on cherche une meilleure combinaison, un meilleur ordre, une meilleure allocation ou une meilleure couverture, la complexité combinatoire n’est jamais loin. Je regarde aussi les formulations qui transforment un oui/non théorique en optimisation réelle : dès qu’on veut “le meilleur” au lieu de “un résultat valide”, le coût peut changer brutalement.
Signes qui doivent vous alerter
- Le problème consiste à choisir un sous-ensemble, une permutation ou une affectation optimale.
- Chaque nouvelle contrainte multiplie le nombre de cas à tester.
- Le temps de calcul double, puis quadruple, puis devient imprévisible dès que l’entrée grandit un peu.
- La solution brute force marche sur un petit jeu de test, puis s’écroule sur des données réelles.
- Le besoin métier demande un optimum global, mais tolère en réalité une solution “assez bonne”.
Lire aussi : Test unitaire - Écrire, lire et juger un test efficace (Exemple Python)
Ce que je vérifie en premier
- Le problème est-il de décision, d’optimisation ou de comptage ?
- Les contraintes sont-elles toutes indispensables, ou certaines peuvent-elles être relâchées ?
- Existe-t-il des bornes naturelles sur la taille d’entrée en production ?
- Une solution approximative ou paramétrée suffit-elle au métier ?
Cette étape de cadrage évite de se battre contre le mauvais problème. Dans beaucoup de logiciels, ce n’est pas l’algorithme qui est mal conçu, c’est l’objectif qui est trop ambitieux par rapport au temps et aux données disponibles. La suite logique consiste donc à choisir une méthode de résolution adaptée, pas à forcer une approche unique.
Que faire quand il faut livrer malgré tout
Face à une difficulté NP-difficile, j’évite le réflexe “il faut absolument une solution exacte”. En production, la bonne réponse est souvent un compromis clair entre qualité, vitesse et stabilité. Parfois, un solveur exact suffit. Parfois, il faut une heuristique. Parfois, une approximation avec garantie théorique est bien plus utile qu’un optimum trouvé trop tard.
| Approche | Quand l’utiliser | Atout principal | Limite à accepter |
|---|---|---|---|
| Recherche exacte avec élagage | Petites instances ou besoin absolu d’optimalité | Résultat exact | Peut exploser sur quelques entrées seulement |
| Programmation dynamique | Quand la structure du problème s’y prête | Très efficace sur certaines variantes | Souvent pseudo-polynomiale, donc pas générale |
| Heuristique | Quand la vitesse compte plus que la preuve d’optimalité | Simple à intégrer, rapide | Pas de garantie sur la qualité finale |
| Approximation | Quand on veut un écart borné par rapport à l’optimum | Cadre mathématique solide | Ne s’applique pas à tous les problèmes |
| Paramétrisation | Quand une partie des données reste petite | Très bon contrôle sur les cas structurés | Dépend d’un paramètre réellement faible |
| Solveur SAT ou ILP | Quand le problème se modélise proprement | Puissant en pratique sur de nombreux cas industriels | La qualité du modèle conditionne tout |
Les outils de type branch and bound méritent aussi l’attention. L’idée est d’explorer l’espace des solutions en coupant tôt les branches qui ne peuvent plus battre la meilleure solution connue. C’est souvent la meilleure option quand on veut rester exact mais qu’on espère réduire fortement la recherche réelle. Dans certains projets, ce n’est pas le problème qui change, c’est la capacité à bien borner le calcul.
- Si le produit doit répondre en moins d’une seconde, une heuristique bien calibrée vaut souvent mieux qu’un optimum tardif.
- Si la qualité doit être démontrable, une approximation ou un solveur avec borne est plus crédible qu’un algorithme artisanal.
- Si les données sont structurées et répétitives, la paramétrisation ou le prétraitement donnent parfois un gain décisif.
- Si le modèle métier est trop riche, simplifier une contrainte peut rapporter plus qu’optimiser le code.
Les erreurs les plus coûteuses avec ces problèmes
Le premier piège consiste à croire qu’une machine plus rapide résout un problème NP-difficile. En réalité, le facteur limitant est structurel : le temps peut croître de façon exponentielle, et un gain matériel ne change pas la nature de cette croissance. Le deuxième piège est d’évaluer l’algorithme sur des données trop petites ou trop faciles, puis d’être surpris quand tout s’effondre en production.
- Confondre NP-difficile et NP-complet, alors que la frontière n’est pas la même.
- Promettre un optimum global alors qu’une bonne solution suffit au besoin métier.
- Ignorer la taille réelle des données et raisonner uniquement sur des cas de démonstration.
- Négliger le prétraitement, qui peut réduire fortement l’espace de recherche.
- Comparer des heuristiques sans fixer de métrique claire de qualité, de temps et de stabilité.
Le plus coûteux, à mon sens, reste le manque de cadrage. Quand un chef de projet demande “le meilleur résultat”, il faut demander en retour : meilleur selon quel critère, sur quelle taille d’entrée, avec quelle tolérance temporelle ? Une réponse honnête à ces trois questions évite beaucoup de fausses attentes. C’est là que la technique rejoint le produit.
Ce qu’il faut garder en tête avant de concevoir la solution
Face à un problème NP difficile, l’enjeu n’est presque jamais de tout résoudre au sens théorique. L’enjeu réel est de construire une solution qui respecte les contraintes du métier, qui reste stable quand les données grossissent et qui échoue de manière prévisible si la charge dépasse ce que l’on a prévu. C’est une approche beaucoup plus utile que la quête d’un algorithme “parfait” qui ne tiendra pas la production.
Mon conseil est simple : partez de la taille d’entrée, de la qualité minimale acceptable et du délai maximal tolérable, puis choisissez la famille d’algorithmes en fonction de ces trois bornes. Si vous avez ces garde-fous, vous pouvez faire un choix rationnel entre exact, approximation, heuristique ou solveur spécialisé. Si vous ne les avez pas, le problème n’est pas seulement difficile : il est mal posé.