
Le tri par insertion en Python est un excellent cas d’école pour comprendre comment un algorithme parcourt une liste, déplace des valeurs et construit progressivement un résultat ordonné. Je vais montrer son mécanisme, son implémentation simple, ses variantes utiles et surtout ses limites réelles, parce qu’en pratique on ne l’emploie pas pour les mêmes raisons qu’un `sorted()` ou qu’un `list.sort()` natif.
Les points essentiels à garder en tête avant d’écrire ce tri
- Le principe est simple: une partie de la liste est déjà triée, et chaque nouvel élément y est inséré à sa bonne place.
- La version classique est stable si l’on ne décale que les éléments strictement supérieurs à la valeur à insérer.
- Sa complexité est de O(n²) au pire, mais elle peut descendre à O(n) si la liste est presque triée.
- Pour un projet réel, les fonctions natives `sorted()` et `list.sort()` restent presque toujours le meilleur choix.
- Le tri par insertion reste très utile pour apprendre à raisonner sur les boucles, les invariants et les déplacements en mémoire.
Ce que fait vraiment le tri par insertion
Je le vois comme un tri “à la main” très proche de ce qu’on fait avec des cartes: on prend une nouvelle valeur, on regarde où elle doit se placer dans la partie déjà ordonnée, puis on décale ce qu’il faut pour lui faire de la place. Le cœur de l’algorithme n’est pas de tout reclasser à chaque étape, mais de conserver une zone triée qui grandit à chaque itération.
Ce détail change tout. À chaque passage, la liste est séparée en deux zones: à gauche, une partie déjà triée; à droite, les éléments qui restent à traiter. C’est ce principe d’invariant de boucle qui rend l’algorithme facile à comprendre et à vérifier.
Autre point important: si l’on conserve l’ordre des éléments égaux, le tri est stable. Cela veut dire que deux valeurs identiques gardent leur ordre d’origine, ce qui compte beaucoup dès qu’on trie des objets, pas seulement des nombres. Une fois cette logique posée, le déroulé pas à pas devient très simple à suivre.
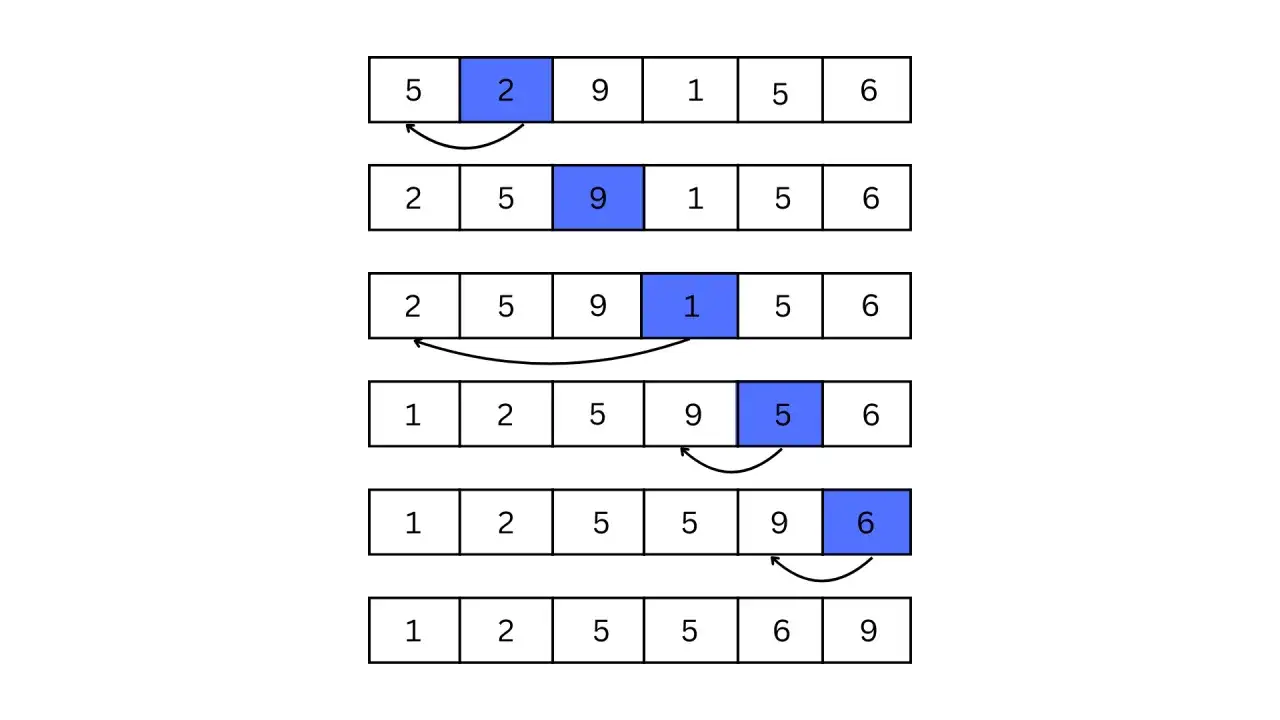
Comment l’algorithme avance élément par élément
Prenons une liste courte, par exemple [7, 3, 5, 2]. Au départ, le premier élément est considéré comme déjà trié. On prend ensuite 3, on le compare à 7, on décale 7 vers la droite, puis on insère 3 au début. La zone triée devient alors [3, 7].
-
Étape 1: la sous-liste
[7]est déjà triée. -
Étape 2: on insère
3avant7, ce qui donne[3, 7]. -
Étape 3: on prend
5, on le compare à7, on décale7, puis on place5entre les deux. -
Étape 4: on prend
2et on décale successivement5,7et3avant de l’insérer tout au début.
Ce mécanisme est intéressant parce qu’il montre la différence entre comparer et déplacer. Dans beaucoup de tris simples, on confond les deux, alors qu’ici on voit clairement que l’algorithme passe surtout son temps à faire glisser les éléments vers la droite pour libérer une place. Cette vue mécanique prépare directement le code.
Écrire une version Python claire et lisible
La version la plus classique tient en quelques lignes. Je préfère la garder simple, car c’est justement sa lisibilité qui permet de comprendre l’algorithme sans bruit inutile.
def tri_par_insertion(liste):
for i in range(1, len(liste)):
valeur = liste[i]
j = i - 1
while j >= 0 and liste[j] > valeur:
liste[j + 1] = liste[j]
j -= 1
liste[j + 1] = valeur
return listeLe point le plus important est la condition liste[j] > valeur. Si l’on utilise strictement >, les éléments égaux ne sont pas déplacés devant les autres, ce qui préserve la stabilité du tri. Si on remplace cette comparaison par >=, on modifie ce comportement et on perd cette propriété.
Je recommande aussi de garder en tête que cette fonction trie la liste sur place. Si tu veux conserver l’originale, il suffit de travailler sur une copie avant d’appeler la fonction. Pour une liste courte ou pour un exercice, cette version est parfaite; pour des données plus sérieuses, il faut ensuite regarder comment l’adapter à des objets réels. C’est là que le besoin de flexibilité apparaît.
L’adapter à des objets et à une clé de tri
Dans un vrai projet, on trie rarement une suite de nombres nus. On trie plutôt des dictionnaires, des tuples ou des objets métiers. Dans ce cas, il devient plus utile de raisonner avec une clé de tri, comme le fait l’API native de Python.
Pour éviter de recalculer la clé à chaque comparaison, je préfère souvent une version qui la stocke à part. C’est plus propre quand la fonction de clé est coûteuse ou quand on trie des structures plus complexes.
def tri_par_insertion_avec_cle(seq, key=lambda x: x):
valeurs = list(seq)
cles = [key(x) for x in valeurs]
for i in range(1, len(valeurs)):
element = valeurs[i]
cle = cles[i]
j = i - 1
while j >= 0 and cles[j] > cle:
valeurs[j + 1] = valeurs[j]
cles[j + 1] = cles[j]
j -= 1
valeurs[j + 1] = element
cles[j + 1] = cle
return valeursUn exemple simple avec des dictionnaires permet de voir l’intérêt tout de suite:
etudiants = [
{"nom": "Lina", "note": 14},
{"nom": "Yanis", "note": 11},
{"nom": "Maya", "note": 14}
]
resultat = tri_par_insertion_avec_cle(etudiants, key=lambda e: e["note"])Ici, les deux étudiants qui ont la même note gardent leur ordre initial si l’algorithme est écrit avec la bonne condition de comparaison. C’est précisément ce genre de détail qui fait la différence entre une démonstration académique et une implémentation réellement fiable. Une fois qu’on sait gérer les clés, la vraie question devient celle du coût et du bon contexte d’utilisation.
Quand le tri par insertion en Python reste pertinent
Je le dis sans détour: pour du code de production, je ne choisis presque jamais cet algorithme pour trier une grande liste entièrement aléatoire. Le coût quadratique devient vite trop lourd. À 1 000 éléments, le pire cas approche déjà un million de comparaisons et de décalages; à 10 000, on grimpe autour de 100 millions. Ce n’est pas un problème théorique, c’est une différence très visible dès que les volumes montent.
La documentation officielle de Python distingue clairement `sorted()` et `list.sort()`: la première renvoie une nouvelle liste triée, la seconde trie sur place. Python s’appuie en pratique sur un tri natif très optimisé, stable, capable d’exploiter les portions déjà ordonnées. Autrement dit, si ton but est simplement de trier vite et proprement, tu n’as pas intérêt à réécrire le moteur toi-même.
| Solution | Coût typique | Quand l’utiliser | Limite principale |
|---|---|---|---|
| Tri par insertion maison | O(n²) au pire, O(n) si la liste est presque triée | Apprentissage, petites listes, exercice algorithmique | Devient lent dès que la taille augmente |
sorted() / list.sort()
|
En pratique O(n log n) | Usage réel, code métier, données générales | Ne montre pas le mécanisme interne du tri |
bisect.insort() |
O(n) par insertion | Maintenir une liste déjà triée au fil des ajouts | Ce n’est pas un tri complet, seulement une insertion ordonnée |
Le vrai bon critère, à mon avis, n’est pas “quel algorithme est le plus simple à coder”, mais “quel algorithme correspond au flux de données”. Si tu reçois une liste déjà presque ordonnée, le tri par insertion peut être étonnamment correct pour de petits volumes. Si tu dois traiter des données volumineuses, je pars directement sur les outils natifs. Et si je veux juste insérer régulièrement une valeur dans une séquence déjà triée, je regarde plutôt du côté de `bisect`.
Ce que cet algorithme t’apprend même si tu n’en fais pas un outil de production
Je trouve que c’est l’un des meilleurs tris pour apprendre à penser comme un programmeur. Il t’oblige à suivre une boucle, à préserver un invariant, à gérer les indices avec précision et à comprendre pourquoi un simple changement de comparaison peut modifier le comportement global. C’est exactement le genre d’exercice qui rend ensuite les autres algorithmes plus lisibles.
Si je devais retenir une seule idée, ce serait celle-ci: le tri par insertion n’est pas là pour battre Python sur la performance, il est là pour t’apprendre comment un tri fonctionne réellement. Une fois cette mécanique comprise, `sorted()`, `list.sort()` et même `bisect.insort()` deviennent beaucoup plus faciles à utiliser au bon endroit. Et c’est souvent ça, la vraie montée en compétence: savoir quand écrire l’algorithme, quand le lire, et quand le laisser faire au runtime.